A Comprehensive Guide to MiXCR: Mastering Immune Repertoire Analysis for Research and Drug Development
This article provides a comprehensive guide to MiXCR, a powerful computational tool for immune repertoire analysis.
A Comprehensive Guide to MiXCR: Mastering Immune Repertoire Analysis for Research and Drug Development
Abstract
This article provides a comprehensive guide to MiXCR, a powerful computational tool for immune repertoire analysis. Covering foundational concepts to advanced applications, we explore MiXCR's three-stage workflow for processing BCR/TCR sequencing data from diverse sources including single-cell and bulk RNA-seq. The guide details practical implementation with protocol-specific presets, troubleshooting strategies for common issues, and validation through performance benchmarking against alternative tools. Designed for researchers, scientists, and drug development professionals, this resource demonstrates how MiXCR's accuracy, speed, and comprehensive functionality can advance immunological research and therapeutic development.
Understanding MiXCR: The Foundation of Modern Immune Repertoire Analysis
Adaptive Immune Receptor Repertoire sequencing (AIRR-seq) involves the use of high-throughput sequencing to capture the diversity of B-cell and T-cell receptors within an individual's immune system. This complex dataset, which can contain millions of sequences, provides profound insights into the dynamic immune response to disease, vaccination, and other interventions [1]. The field is coordinated by the AIRR Community, a multidisciplinary group that establishes standards for data generation, annotation, and sharing to ensure reproducibility and interoperability [2]. The analysis of AIRR-seq data requires sophisticated computational tools to translate raw sequencing reads into biologically meaningful information on gene usage, CDR3 properties, clonal lineage structure, and sequence diversity [1].
MiXCR is a comprehensive software pipeline specifically designed for the analysis of AIRR-seq data. It provides an end-to-end solution, processing raw sequencing data from FASTQ files into annotated clonotype tables ready for downstream biological interpretation [3]. Its capability to analyze data from a wide variety of library preparation protocols and commercial kits, coupled with its high accuracy and sensitivity, has made it a cornerstone tool in modern immunogenetics research [3] [4].
MiXCR Analytical Workflow: From Raw Data to Clonotypes
The analysis in MiXCR is typically divided into two main parts: upstream analysis of raw sequencing data and downstream analysis of repertoire tables [3]. The exact steps are optimized based on the data type and wet-lab protocol.
Upstream Analysis Steps
- Alignment: The initial step aligns raw sequencing reads against a reference database of V, D, J, and C gene segments. MiXCR employs a highly efficient k-mer seed-and-vote approach, followed by more precise Smith-Waterman or Needleman-Wunsch algorithms for optimal alignment. For paired-end data, it expertly merges overlapping mate pairs, and it can also trim low-quality nucleotides from read edges [3].
- Tag Refinement: For barcoded data (e.g., containing UMIs), this critical step corrects errors within barcode sequences and filters out spurious barcodes arising from PCR chimerism or empty droplets, thereby eliminating artificial diversity [3].
- Partial Assembly and CDR3 Extension: For fragmented data (e.g., RNA-Seq), MiXCR rescues alignments that only partially cover the CDR3 region by identifying and merging reads originating from the same molecule. For TCR data, it can safely impute missing nucleotides at the CDR3 edges using germline reference sequences [3].
- Clonotype Assembly: This is the key step where sequences are grouped into clonotypes. MiXCR applies multiple layers of error correction [5]:
- Quality-guided mapping rescues reads with low-quality nucleotides by mapping them to assembled core clonotypes.
- PCR error correction uses fuzzy clustering to build hierarchical trees where low-count clonotypes are attached to highly similar "parent" clonotypes with significantly higher counts, filtering out PCR errors.
- For barcoded data, it first builds consensus "pre-clones" for groups of reads sharing the same barcode.
- Contig Assembly: For fragmented data, MiXCR uses an alignment-guided algorithm to reconstruct the longest available consensus contig sequence for each receptor, which is essential for analyzing features like somatic hypermutations in B-cells [3].
- Export: The final step of upstream analysis exports exhaustive clonotype tables containing nucleotide and amino acid sequences, gene assignments, mutations, abundance, and other features, in tabular, AIRR Community-standard, or human-readable formats [3] [6].
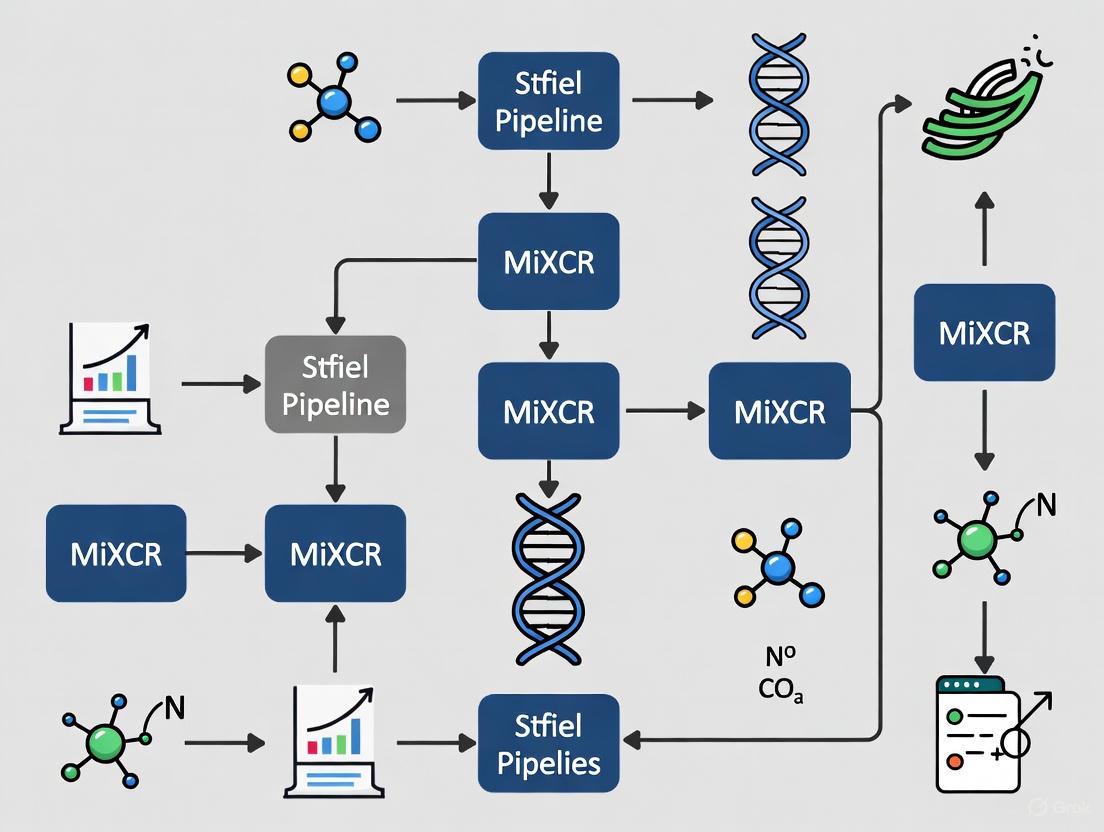
The following diagram illustrates the logical workflow and data transformation at each stage of the MiXCR upstream analysis pipeline.
Downstream Analysis and Visualization
Once clonotype tables are generated, MiXCR enables a wealth of downstream analyses to extract biological insights, many of which can be visualized directly through its exportPlots functionality [7].
- Gene Usage: Analyzes the distribution of V, D, and J genes. Skewing in V-J pairing can indicate an antigen-specific response. MiXCR can generate heatmaps or bar plots to visualize this usage [7].
- CDR3 Analysis: The CDR3 is the most variable part of the receptor. MiXCR can calculate and visualize properties like length (in amino acids or nucleotides), hydrophobicity, charge, and other physicochemical properties, which can reveal shared motifs among receptors binding the same epitope [1] [7].
- Diversity Metrics: Diversity unites the number of distinct clones and their distribution. MiXCR computes various metrics, including:
- Observed Diversity: The simple count of distinct clonotypes.
- Shannon-Wiener Index: Measures the uncertainty in predicting the identity of a randomly chosen clonotype.
- Inverse Simpson Index: Weights towards the abundance of the most dominant clonotypes.
- Chao1 Estimator: Estimates total species richness, accounting for undetected clonotypes.
- Gini Index: Measures the inequality in clonal abundance distribution [7].
- Clonal Dynamics: The distribution of clone sizes is highly informative. Visualizations include rank-frequency plots (which reveal clonal expansion) and clonal abundance binning, which groups clones by frequency (e.g., 0.1-1%, 0.01-0.1%) to summarize repertoire architecture [1].
- Overlap Analysis: Calculates pairwise similarity or overlap between different repertoires (e.g., from different time points or tissue samples), which can be visualized as heatmaps [7].
Table 1: Key Downstream Diversity Metrics Available in MiXCR
| Metric | Description | Biological Interpretation |
|---|---|---|
| Observed Diversity | Simple count of distinct clonotypes. | A direct measure of repertoire richness. |
| Shannon-Wiener Index | Measure of uncertainty in clonotype identity. | Higher values indicate greater richness and evenness. |
| Inverse Simpson Index | Probability that two randomly sampled sequences belong to different clonotypes. | Weights towards dominant clones; less sensitive to rare clones. |
| Chao1 Estimator | Estimates total species richness. | Infers true diversity, correcting for undetected rare clonotypes. |
| Gini Index | Measures inequality in clonal abundance distribution. | A value of 0 indicates perfect equality; 1 indicates maximal inequality (one dominant clone). |
Experimental Protocols and Practical Implementation
The Scientist's Toolkit: Research Reagent Solutions
MiXCR's strength lies in its compatibility with a vast array of commercial kits and custom protocols. The software uses "presets" – pre-configured analysis pipelines optimized for specific data types [4].
Table 2: Selected Commercial Kits and Corresponding MiXCR Presets
| Kit / Protocol Name | Provider | Template | Key Features | MiXCR Preset |
|---|---|---|---|---|
| Single Cell VDJ | 10x Genomics | cDNA (Single Cell) | Full-length V(D)J for paired BCR/TCR from single cells. | 10x-sc-xcr-vdj |
| NEBNext Immune Sequencing Kit | New England BioLabs | RNA (UMI) | Full-length repertoires for BCR heavy/light and TCR alpha/beta chains. | neb-human-rna-xcr-umi-nebnext |
| DriverMap AIR Profiling | Cellecta | DNA / RNA (UMI) | Targets functional CDR3 regions; available for human and mouse. | cellecta-human-dna-xcr-umi-drivermap-air |
Example Protocol: Targeted BCR Multiplex cDNA Libraries
The following protocol is adapted from a published study on tumor-infiltrating B cells in mice [8].
1. Sample Preparation and B-Cell Isolation:
- B cells are isolated from tissues of interest (e.g., bone marrow, blood, lymph nodes, tumor).
- Cells are incubated with a mixture of anti-IgG, anti-IgM, and anti-CD138 magnetic beads to enrich for B-cell populations.
2. Library Construction for Sequencing:
- Total RNA Isolation: Extract total RNA from the isolated B cells.
- First-Strand cDNA Synthesis: Perform reverse transcription using SuperScript III and Oligo (dT) primers.
- First PCR (Target Amplification): Amplify the variable heavy (VH) Ig genes using a multiplex of 19 forward primers annealing to Framework 1 (FR1) and two reverse primers binding to the IgM and IgG constant regions. These primers include a "step-out" (glue) sequence for the subsequent PCR.
- Second PCR (Adapter Attachment): Use the product from the first PCR as a template to attach full Illumina adaptors and sample indices via primer extension.
3. Sequencing and Analysis with MiXCR:
- Sequence the final libraries on an Illumina MiSeq platform (e.g., 2 × 300 bp paired-end).
- Analyze the resulting FASTQ files using the appropriate MiXCR preset for a multiplexed, targeted BCR assay. The analysis will align reads, correct errors, assemble clonotypes, and export data for further investigation of repertoire differences between tissues.
MiXCR represents a critical computational framework within the ecosystem of immunogenetics, enabling robust and reproducible analysis of adaptive immune receptor repertoires. Its seamless workflow from raw sequencing data to biologically interpretable results, combined with its adherence to AIRR Community standards, makes it an indispensable tool for researchers and drug development professionals. By leveraging MiXCR, scientists can systematically decode the complexities of the immune repertoire, advancing our understanding of immune responses in health, disease, and therapeutic intervention.
MiXCR is a comprehensive computational toolkit designed for the analysis of T-cell receptor (TCR) and B-cell receptor (BCR) repertoires from various sequencing data types. Its robust architecture enables researchers to process everything from bulk RNA sequencing to complex single-cell data, providing a unified solution for immunology research and therapeutic drug development [9] [10]. The software implements optimized presets for numerous library preparation protocols and sequencing technologies, ensuring accurate results across diverse experimental designs while maintaining exceptional processing speed and sensitivity [9] [3].
The adaptability of MiXCR to different data inputs addresses a critical need in modern immunology research, where studies increasingly integrate multiple sequencing approaches to comprehensively understand immune responses. By supporting both bulk and single-cell RNA-seq data within the same analytical framework, MiXCR facilitates seamless comparative analyses and enhances reproducibility across studies [10].
Supported Data Types and Analysis Frameworks
Comprehensive Data Type Compatibility
MiXCR's analytical capabilities span the entire spectrum of modern sequencing approaches used in immune repertoire studies. The platform's flexibility allows researchers to maintain consistent analytical parameters across different experimental modalities, enabling direct comparisons between studies utilizing different sequencing technologies [9] [3].
Table: MiXCR Data Type Compatibility and Analysis Features
| Data Type | Supported Protocols | Key Analysis Features | Optimal Use Cases |
|---|---|---|---|
| Single-Cell RNA-seq | 10x Genomics 5' V(D)J, GEM-X (5' v3) chemistry | Paired-chain analysis, cell barcode processing, cross-contamination removal | Clonal diversity at cellular level, TCR/BCR pairing identification |
| Bulk RNA-seq | Standard RNA-seq, non-enriched transcriptome | CDR3 extraction, partial assembly, error correction | Repertoire diversity assessment, clone tracking across samples |
| Targeted Immune Sequencing | QIAseq Immune Repertoire RNA Library Kit | UMI-based error correction, full-length receptor sequencing | High-accuracy clonotype quantification, minimal PCR bias |
| Genomic DNA | TCR/BCR gene rearrangement sequencing | Non-functional rearrangement detection, combinatorial diversity assessment | Total repertoire diversity including non-productive rearrangements |
The software's compatibility with single-cell technologies is particularly valuable for studying immune cell heterogeneity and receptor chain pairing, which are essential for understanding antigen specificity [9]. For bulk RNA-seq analyses, MiXCR implements specialized algorithms like CDR3 extension and partial assembly to rescue receptor sequences from fragmented transcriptome data [3]. This capability leverages RNA-seq data beyond conventional gene expression analysis, extracting valuable immune repertoire information without requiring specialized targeted sequencing [10].
Template-Specific Analysis Considerations
MiXCR accommodates different starting templates, each with distinct advantages for specific research questions. The choice of template—genomic DNA (gDNA), RNA, or cDNA—significantly influences the biological interpretation of repertoire data [10].
For gDNA templates, MiXCR captures both productive and non-productive TCR/BCR rearrangements, providing a comprehensive view of potential immune diversity, including sequences not expressed at the protein level. This approach is ideal for quantifying relative clonal abundance within a population. In contrast, RNA/cDNA templates focus exclusively on the expressed, functional repertoire, reflecting active immune responses. While RNA templates are more susceptible to technical biases during reverse transcription, they offer direct insight into immunologically relevant clonotypes [10].
Core Analytical Workflow and Algorithms
Upstream Analysis Pipeline
MiXCR's upstream processing transforms raw sequencing data into annotated clonotypes through a multi-step analytical pipeline. Each step incorporates specialized algorithms optimized for different data types and library preparation methods [3].
Alignment and Preprocessing: The initial step employs a k-mer seed-and-vote approach for rapid alignment to reference V-, D-, J-, and C-gene segments, followed by more precise Needleman-Wunsch or Smith-Waterman algorithms for optimal alignment. For paired-end data, MiXCR implements sophisticated mate-pair merging that can overlap reads with as little as one nucleotide of overlap. The alignment step also extracts barcode sequences using a powerful pattern-matching language capable of handling diverse barcode designs [3].
Tag Refinement: This crucial step corrects errors within barcode sequences and filters spurious barcodes arising from multiple sources, including PCR errors, chimeric molecule formation, exploded cells, or empty droplets. By eliminating artificial diversity caused by these technical artifacts, tag refinement significantly improves data quality, particularly for single-cell experiments where spurious barcodes can comprise up to 90% of data [3].
Partial Assembly and CDR3 Extension: For fragmented data types like RNA-seq, MiXCR implements a partial assembly algorithm that identifies and merges alignments from the same molecule across different reads to reconstruct complete CDR3 regions. For TCR data from non-enriched RNA-seq, an optional CDR3 extension step imputes missing nucleotides at CDR3 edges using germline gene segment information, effectively rescuing valuable sequence information that would otherwise be lost [3].
Clonotype Assembly and Error Correction: The core assembly process groups alignments by similar nucleotide sequences using fuzzy matching and clustering techniques. MiXCR applies two layers of error correction: quality-guided mapping to address sequencing errors, and specialized heuristic multi-layer clustering to correct PCR errors while preserving real biological variations like hypermutations or allelic variants [3].
Contig Assembly: For fragmented data, MiXCR reconstructs the longest available consensus contig sequences using an alignment-guided algorithm. This step is particularly valuable for B-cell data, as it detects hypermutations outside the CDR3 region and discriminates them from technical errors, enabling more accurate clonotype definition [3].
MiXCR Upstream Analysis Workflow: This diagram illustrates the multi-step processing pipeline that transforms raw sequencing data into annotated clonotype tables, with pathway branching for different data types.
Downstream Analysis Capabilities
Following upstream processing, MiXCR provides extensive downstream analytical functionalities for biological interpretation. These include somatic hypermutation tree construction for B-cells, allele inference, CDR3 characteristic analysis (assessing physicochemical properties like hydrophobicity and charge), diversity measures (Normalized Shannon-Wiener, Chao1, Gini Index), segment usage analysis, and pairwise distance analysis [9].
The software generates comprehensive quality control reports and visualizations, including percent alignment metrics, chain usage distributions, and UMI/cell barcode distribution plots. These QC tools enable researchers to assess data quality and identify potential technical issues that might affect interpretation [9].
Experimental Protocols and Implementation
Standardized Analysis Presets
MiXCR simplifies implementation through predefined analysis presets optimized for specific sequencing technologies and library preparation protocols. These presets automatically configure the appropriate parameters and workflow steps, making sophisticated immune repertoire analysis accessible to non-bioinformaticians [3].
For 10x Genomics single-cell V(D)J data, the preset command is straightforward:
For QIAseq Immune Repertoire RNA Library data, the dedicated preset handles UMI processing and library-specific parameters:
These one-line commands execute the complete optimized workflow, from raw sequencing data to final clonotype tables, while allowing customization of key parameters like species specification (--species hsa for human) [9] [11].
Essential Research Reagent Solutions
Table: Key Research Reagents and Their Functions in Immune Repertoire Studies
| Reagent/Kit | Primary Function | Compatible Data Type | MiXCR Preset |
|---|---|---|---|
| 10x Genomics Chromium Next GEM Single-Cell 3' Reagent Kit v3.1 | Single-cell partitioning, barcoding, cDNA synthesis | Single-cell RNA-seq with V(D)J | 10x-sc-xcr-vdj |
| QIAseq Immune Repertoire RNA Library Kit | Targeted TCR/BCR enrichment with UMIs | Bulk RNA with immune specificity | qiagen-human-rna-tcr-umi-qiaseq |
| Takara Human BCR Full-Length Kit | Full-length BCR amplification | Bulk B-cell receptor sequencing | takara-human-bcr-full-length |
| Standard RNA-seq Library Prep Kits | Whole transcriptome library preparation | Bulk RNA-seq data | rnaseq-cdr3 |
Advanced Applications and Integration Strategies
Multi-Modal Data Integration
MiXCR supports integrative analyses that combine different data types to address complex immunological questions. The platform enables correlation of clonotype information with gene expression data, allowing researchers to link specific immune receptors to functional cell states [9]. This capability is particularly powerful when analyzing single-cell multi-omics data, where TCR/BCR sequences and transcriptomes are captured simultaneously from the same cells.
For drug development applications, MiXCR facilitates the identification of therapeutic antibody candidates by analyzing BCR repertoires from bulk sequencing data. The software's ability to reconstruct full-length antibody sequences, identify somatic hypermutations, and infer clonal lineage relationships provides valuable insights for selecting candidates with desired specificity and affinity characteristics [10].
Customization and Scalability
While MiXCR provides convenient presets for common protocols, it also offers extensive customization options for advanced users. Researchers can modify alignment parameters, error correction stringency, and clonotype grouping criteria to address specific research questions. The software efficiently scales from small-scale experiments to large cohort studies, with benchmarking tests demonstrating superior processing speed and sensitivity compared to alternative tools like TRUST4 and Immcantation [9].
For computational environments with specific requirements, MiXCR supports both step-by-step execution for better hardware utilization and one-line analyze commands for workflow simplicity. This flexibility enables researchers to optimize computational resource usage based on their data processing needs and available infrastructure [3].
MiXCR provides a comprehensive, flexible solution for immune repertoire analysis across diverse data types, from single-cell to bulk RNA-seq. Its robust analytical pipeline, combined with protocol-specific optimizations and extensive downstream analysis capabilities, makes it an indispensable tool for researchers studying adaptive immune responses in basic immunology, clinical research, and therapeutic development contexts. The software's continuous development and widespread adoption—with over 10 million samples analyzed and citation in more than 1,600 academic papers—underscore its reliability and performance in generating biologically meaningful insights from complex immune sequencing data [9].
Immune repertoire sequencing is a powerful technique for profiling the diversity of T- and B-cell receptors in a biological sample, with critical applications in vaccine development, cancer immunology, and autoimmune disease research. MiXCR (MiLaboratory Toolkit for Immune Repertoire Analysis) has emerged as a cornerstone computational pipeline for this task, enabling researchers to efficiently translate raw sequencing data into biologically meaningful insights. Its robust, multi-stage workflow ensures high accuracy and sensitivity. This protocol details the standardized three-stage MiXCR process, encompassing 1) upstream processing of raw sequencing reads into clonotypes, 2) comprehensive quality control (QC) to assess data integrity, and 3) downstream secondary analysis for functional and diversity assessment. Adherence to this structured workflow is essential for generating reliable, reproducible, and interpretable immune repertoire data.
Upstream Analysis: From Raw Sequencing Data to Clonotypes
The upstream analysis is the foundational stage where MiXCR processes raw sequencing data to identify and quantify distinct T- or B-cell receptor clonotypes. This involves several automated steps to align, error-correct, and assemble sequences [3].
- 1.1 Alignment: The initial step aligns raw sequencing reads against a reference database of V, D, J, and C gene segments. MiXCR employs a family of efficient algorithms, starting with a fast k-mer seed-and-vote approach and refining alignments with Needleman–Wunsch or Smith–Waterman algorithms. For paired-end data, it merges overlapping mate pairs with high precision, even with minimal overlap. This step also extracts barcode sequences (e.g., UMIs, cell barcodes) if present [3].
- 1.2 Tag Refinement: For barcoded data, this step is critical for correcting errors within barcode sequences and filtering out spurious barcodes that can arise from PCR errors, sequencing artifacts, or empty droplets in single-cell protocols. This process eliminates artificial diversity, ensuring that clonotype counts are accurate [3].
- 1.3 Partial Assembly and CDR3 Extension: In fragmented data (e.g., RNA-Seq, 10x Genomics), some reads may only partially cover the CDR3 region. MiXCR identifies and merges these partial alignments to reconstruct complete CDR3 sequences. For TCR data, an additional CDR3 extension step can impute a few missing nucleotides at the CDR3 edges using germline gene information, rescuing otherwise lost data [3].
- 1.4 Clonotype Assembly: This is the core step where alignments are grouped into clonotypes. MiXCR groups sequences by similarity in a defined gene feature (e.g., CDR3 nucleotide sequence). For barcoded data, it first builds consensus sequences for each unique molecular identifier (UMI) to account for PCR and sequencing errors. A multi-layer clustering algorithm then corrects residual PCR errors and distinguishes them from real somatic hypermutations in B-cells [3].
- 1.5 Contig Assembly: For fragmented data, this step assembles the longest possible consensus contig sequence for each clonotype. This alignment-guided algorithm can detect hypermutations outside the CDR3, allowing a single initial clonotype to be split into multiple hypermutation-based variants, which is crucial for B-cell repertoire analysis [3].
- 1.6 Export: The final step of upstream analysis exports the assembled clonotypes into a tabular text file or AIRR-compliant format. The output includes exhaustive information such as clonotype abundance, CDR3 nucleotide and amino acid sequences, V/D/J gene assignments, and mutation information [12] [3].
Table 1: Key MiXCR analyze Presets for Common Data Types
| Preset Name | Typical Application | Key Optimizations |
|---|---|---|
10x-vdj-bcr [3] |
10x Genomics Single-Cell BCR Data | Handles cell barcodes, UMIs, and fragmented reads. |
takara-human-bcr-full-length [3] |
Takara Bio Full-length BCR Profiling | Optimized for full-length VDJRegion assembly. |
rnaseq-cdr3 [3] |
Non-enriched RNA-Seq Data | Employs partial assembly and CDR3 extension. |
qiagen-human-rna-tcr-umi-qiaseq [11] |
QIAseq Targeted RNA TCR UMI Libraries | Configured for specific UMI location and library structure. |
Figure 1: The MiXCR Upstream Analysis Workflow. The pathway illustrates the stepwise processing of raw sequencing data into clonotype tables, with conditional steps for different data types.
Quality Control (QC) and Troubleshooting
A rigorous QC step is imperative to validate the data and the analysis. MiXCR provides integrated tools to generate comprehensive QC reports, helping to distinguish between wet-lab issues and misapplied analysis settings [13].
- 2.1 Generating QC Reports: When using the
analyzecommand, a summary QC report is automatically printed. For a detailed report from an existing clonotype file (.clns), the commandmixcr qc clonotypes.clnsis used [13] [14]. - 2.2 Interpretation of Key QC Metrics: The QC report provides multiple metrics, each with an OK/WARN status. Understanding these metrics is crucial for troubleshooting.
Table 2: Essential MiXCR Quality Control Metrics and Interpretation
| QC Metric | Target Value | Explanation & Troubleshooting Guide |
|---|---|---|
| Successfully aligned reads [14] | >80-90% | Low rates indicate wet-lab problems (e.g., poor library enrichment) or incorrect species reference. |
| Off target (non TCR/IG) reads [14] | Low percentage | A high percentage suggests primer mis-annealing, DNA contamination, or incorrect species. |
| Reads with no V or J hits [14] | Low percentage | High values can result from incorrect read orientation (e.g., from pre-processing) or using an amplicon preset for fragmented data. |
| Overlapped paired-end reads [14] | Protocol-dependent | High overlap is expected for long-read amplicon protocols; low overlap may indicate failed size selection. |
| Reads used in clonotypes [14] | High percentage | A low percentage signals underlying issues reflected in other QC metrics, such as high rates of off-target reads or failed alignments. |
| UMI artificial diversity eliminated [14] | <50% | High rates indicate poor UMI sequencing quality or issues with UMI diversity in the wet-lab protocol. |
- 2.3 Advanced QC Visualization: MiXCR can generate graphical QC reports for deeper investigation:
- Alignment Summary:
mixcr exportQc align *.vdjca alignQc.pdfprovides an overview of alignment performance across samples [13]. - Chain Usage:
mixcr exportQc chainUsage results/*.clns chainUsage.pdfshows the distribution of TCR or IG chains [13]. - Barcode Coverage: For single-cell data,
mixcr exportQc tags 10x-data.clns barcodesFiltering.pdfvisualizes UMI and cell barcode distributions and filtering thresholds [13].
- Alignment Summary:
Downstream Secondary Analysis
Once high-quality clonotype tables are generated, downstream analysis extracts biological insights. MiXCR offers a suite of tools for this stage, and data can also be exported to specialized platforms like Immunarch [15] or Platforma [16] for further exploration.
- 3.1 Loading Data into Analysis Tools: The exported clonotype tables (
.txt) are the standard input for downstream tools. For example, in the R packageimmunarch, data is loaded using therepLoad()function, which can process a single file or a directory of files with an associated metadata table [15]. - 3.2 Key Downstream Analyses: MiXCR facilitates a wide range of secondary analyses [9]:
- Diversity Analysis: Calculation of various diversity measures such as Normalized Shannon-Wiener index, Chao1 estimator, and Gini index to quantify repertoire richness and evenness.
- Somatic Hypermutation (SHM) Analysis: For B-cells, MiXCR can construct SHM trees to study affinity maturation and infer ancestral germline sequences.
- Segment Usage Analysis: Identification of over- or under-represented V, D, and J genes across different sample conditions.
- CDR3 Characterization: Analysis of physicochemical properties of CDR3 amino acid sequences, including hydrophobicity, charge, and volume.
- Clonotype Tracking: Comparing clonotype abundance and distribution across multiple samples or time points.
Experimental Protocol: Analysis of a 5'RACE BCR Dataset
This protocol provides a detailed methodology for analyzing a B-cell receptor repertoire generated from a 5'RACE-based library preparation protocol, a common technique for full-length repertoire profiling.
4.1 The Scientist's Toolkit
- Raw Sequencing Data: Paired-end FASTQ files (e.g.,
sample_R1.fastq.gz,sample_R2.fastq.gz). - MiXCR Software: Installed and licensed version of MiXCR (requires Java 11) [9].
- Computational Resources: A standard desktop or server with multiple CPUs and sufficient RAM (>=8 GB recommended for large datasets).
- Reference Library: The built-in MiXCR reference library for the appropriate species (e.g.,
hsafor Homo sapiens).
- Raw Sequencing Data: Paired-end FASTQ files (e.g.,
4.2 Step-by-Step Procedure
- Execute Upstream Analysis with Preset. The most efficient and robust method is to use a dedicated preset. For a 5'RACE human BCR dataset, the command is [3]:
This single command executes the entire upstream workflow, including alignment, UMI refinement, assembly, and export, generating
.clnsand.tsvfiles. - Perform Quality Control. Generate and inspect the QC report [13] [14]: Pay close attention to "Successfully aligned reads" and "Reads used in clonotypes." For a well-prepared 5'RACE library, these values should be high (>80%).
- (Optional) Advanced Export. Export the final clonotypes with a custom set of fields. For instance, to include only functional clones and export isotype information [12]:
- Proceed to Downstream Analysis. Load the
sample.clones.IGH.tsvfile into an R environment for analysis withimmunarchor another tool [15]:
- Execute Upstream Analysis with Preset. The most efficient and robust method is to use a dedicated preset. For a 5'RACE human BCR dataset, the command is [3]:
This single command executes the entire upstream workflow, including alignment, UMI refinement, assembly, and export, generating
The three-stage MiXCR workflow provides a comprehensive, standardized, and highly accurate pipeline for immune repertoire analysis. By rigorously following the upstream processing, quality control, and downstream analysis steps outlined in this protocol, researchers can confidently transform raw sequencing data into robust, biologically significant findings. The software's continuous development, extensive presets, and integration with a broader ecosystem of analysis tools make it an indispensable resource for advancing research in immunology and therapeutic drug development.
Immune repertoire sequencing has evolved from merely cataloging CDR3 sequences to creating comprehensive maps that link T-cell and B-cell receptor sequences to cell state, location, and function [17]. This transformation enables researchers to move from static lists of clonotypes to dynamic biological stories that track clonal evolution across time and tissue sites. Central to this advancement is the development of sophisticated computational pipelines capable of processing complex immune repertoire data across diverse species and receptor types.
MiXCR has emerged as a leading analysis tool in this domain, with over 10 million samples analyzed and citation in more than 1,600 academic papers [9]. Its utility extends beyond conventional human and mouse TCRα/β and BCR heavy/light chain analyses to include unconventional immune receptors and non-standard species, providing researchers with unprecedented flexibility in experimental design. This application note details MiXCR's capabilities for analyzing diverse species and receptor types, with specific protocols for extending immune repertoire studies beyond conventional models.
Supported Species and Custom Reference Libraries
MiXCR provides extensive species support through multiple reference library options, enabling comparative immunology studies across model organisms and non-standard species.
Built-in Species Support
The platform includes built-in support for common model organisms while maintaining extensibility for non-conventional species [9] [4]. The table below summarizes MiXCR's species compatibility:
Table 1: Species Support in MiXCR
| Species | Designation in MiXCR | Supported Receptor Types | Key Applications |
|---|---|---|---|
| Human | hs, HomoSapiens, hsa |
TCR (α, β, γ, δ), BCR (heavy, light) | Cancer immunology, autoimmunity, infectious disease |
| Mouse | musmusculus, mmu |
TCR (α, β, γ, δ), BCR (heavy, light) | Preclinical models, immunology research |
| Rabbit | Not specified | IGH, IGK, IGL | Antibody discovery, comparative immunology |
| Sheep | Not specified | IGH, IGK, IGL | Veterinary immunology, agricultural research |
| Alpaca | Not specified | VHH domains | Single-domain antibody research |
Recent updates have expanded non-human species support, with version 4.7.0 adding rabbit and sheep immunoglobulin references (IGH, IGK, IGL) and correcting V-gene UTR mapping in the alpaca reference [18]. This continuous expansion facilitates research in agricultural animals, veterinary species, and specialized antibody models.
Custom Reference Libraries
For species not included in built-in libraries, MiXCR supports custom reference libraries [9]. This functionality is particularly valuable for:
- Non-model organisms used in ecological immunology
- Veterinary species with agricultural or conservation importance
- Exotic species used in comparative immunology studies
Custom libraries enable alignment of immune repertoire data using the same rigorous algorithms applied to standard references, ensuring consistent analysis quality across diverse species.
Unconventional Immune Chain Analysis
Beyond conventional αβ T-cell receptors and immunoglobulin chains, MiXCR supports analysis of unconventional immune receptors critical for specialized immune responses.
Gamma Delta (γδ) T-Cell Receptors
MiXCR facilitates γδ TCR repertoire analysis, enabling characterization of these non-conventional T-cells that function at the interface between innate and adaptive immunity [9]. Unlike αβ T-cells that recognize peptide antigens presented by MHC molecules, γδ T-cells recognize unprocessed antigens and play crucial roles in:
- Cancer immunosurveillance through direct recognition of stress antigens
- Epithelial barrier immunity and tissue homeostasis
- Rapid response to pathogens without conventional antigen presentation
The software correctly pairs γ and δ chains from single-cell data, enabling studies of chain pairing preferences and functional characterization of γδ T-cell clonotypes.
Mucosal-Associated Invariant T (MAIT) Cells
Research using MiXCR has revealed coordinated usage of specific V-genes in MAIT cells, particularly the highly correlated usage of TRAV1-2 and TRBV6-4 [19]. This specialized T-cell population:
- Recognizes vitamin B metabolites presented by MR1 molecules
- Exhibits conserved TCR usage patterns across individuals
- Provides rapid defense against bacterial pathogens
MiXCR's ability to detect and quantify these coordinated V-gene usage patterns enables researchers to study MAIT cell dynamics in various disease contexts.
Experimental Protocols
Protocol 1: Cross-Species Immune Repertoire Profiling
This protocol enables immune repertoire analysis across diverse species using custom reference libraries.
Materials and Reagents
- RNA or DNA samples from species of interest
- Library preparation kit compatible with target species
- MiXCR software (version 4.6.0 or higher)
- Custom reference library for target species
Workflow
Step-by-Step Procedure
Sample Preparation
- Extract high-quality RNA/DNA from target species tissues
- Quantify using fluorometric methods
- Assess integrity (RIN > 8 for RNA)
Library Preparation
- Select library prep kit compatible with target species
- Use species-specific V-gene primers if available
- Include UMIs for error correction and quantitative accuracy
Sequencing
- Perform paired-end sequencing on Illumina platform
- Adjust read length based on target region (≥150bp for full-length)
Custom Reference Library Creation
- Compile V, D, J, and C gene sequences from genomic resources
- Format according to MiXCR library specifications
- Validate with control data if available
MiXCR Analysis
Downstream Analysis
- Calculate diversity metrics (Shannon-Wiener, Chao1)
- Perform clonal tracking and lineage analysis
- Compare repertoire features across species
Protocol 2: Gamma Delta (γδ) TCR Analysis from Single-Cell Data
This protocol details γδ TCR profiling from single-cell RNA sequencing data.
Materials and Reagents
- Single-cell suspension from tissue of interest
- 10x Genomics Single Cell Immune Profiling kit
- Feature barcoding antibodies (optional)
- MiXCR with 10x Genomics preset
Workflow
Step-by-Step Procedure
Single-Cell Library Preparation
- Prepare single-cell suspension with high viability (>90%)
- Target cell recovery: 5,000-10,000 cells
- Use 10x Genomics Single Cell Immune Profiling solution
- Include feature barcoding for surface protein expression
VDJ Library Construction
- Enrich for TCR transcripts including γ and δ chains
- Maintain cell barcodes and UMIs
- Pool libraries appropriately for sequencing depth
Sequencing
- Sequence VDJ libraries with sufficient depth (≥5,000 reads/cell)
- Include gene expression libraries for multimodal analysis
MiXCR Analysis with 10x Preset
Gamma Delta Specific Analysis
- Filter clonotypes to include only γ and δ chains
- Analyze chain pairing patterns
- Correlate γδ clonotypes with cell surface phenotypes
Integration with Transcriptomic Data
- Cluster cells based on gene expression profiles
- Identify γδ T-cell subsets based on transcriptional states
- Correlate clonotype usage with functional signatures
Research Reagent Solutions
Table 2: Essential Research Reagents for Extended Immune Repertoire Profiling
| Reagent/Kits | Manufacturer | Function | Compatible Species |
|---|---|---|---|
| DriverMap AIR TCR-BCR Profiling | Cellecta | Targeted CDR3 amplification | Human, Mouse |
| NEBNext Immune Sequencing Kit | New England BioLabs | Full-length repertoire with UMIs | Human, Mouse |
| Single Cell Immune Profiling | 10x Genomics | Paired-chain single cell V(D)J | Human, Mouse (10x-certified) |
| SMART-Seq Mouse BCR | Takara | Full-length BCR with UMIs | Mouse |
| IDT Archer Immunoverse | IDT | Targeted immune repertoire | Human |
| MiLaboratories RNA Multiplex | MiLaboratories | Full-length IG/TCR with isotyping | Human |
Advanced Applications and Integration
Multimodal Single-Cell Analysis
MiXCR enables integration of immune receptor sequencing with other cellular modalities, providing comprehensive immunological insights [9] [17]. This integrated approach allows researchers to:
- Link clonotype to cell state by associating TCR/BCR sequences with transcriptional profiles
- Identify antigen-specific clones through integration with tetramer staining or CITE-seq
- Track clonal dynamics across tissues, timepoints, and disease states
- Characterize rare populations such as antigen-specific B-cells or tissue-resident T-cells
Somatic Hypermutation Analysis
For B-cell receptor analysis, MiXCR provides sophisticated somatic hypermutation (SHM) tree reconstruction [9] [18]. Version 4.6.0 introduced combined heavy+light chain SHM trees from single-cell data, enabling:
- Comprehensive lineage tracing of B-cell maturation
- Analysis of clonal relationships between heavy and light chains
- Characterization of affinity maturation processes
- Vaccine response evaluation through temporal SHM analysis
Troubleshooting and Optimization
Common Challenges
- Low alignment rates: Verify species specification and reference library compatibility
- Incomplete chain recovery: Adjust
--assemble-clonotypes-byparameter based on read length - High contamination signals: Implement whitelist filtering for cell barcodes
- Poor chain pairing: Optimize single-cell viability and library preparation quality
Performance Optimization
- Memory allocation: Adjust JVM parameters for large datasets
- Parallel processing: Utilize multiple cores for alignment steps
- Batch processing: Implement sample batching for high-throughput studies
MiXCR provides comprehensive capabilities for immune repertoire analysis across diverse species and receptor types, enabling researchers to extend their investigations beyond conventional human and mouse αβ T-cell and B-cell receptors. Support for unconventional chains like γδ TCRs and custom species references opens new possibilities for comparative immunology and specialized immune cell studies. The continuous development of new features, including enhanced somatic hypermutation analysis and multimodal single-cell integration, ensures MiXCR remains at the forefront of immune repertoire bioinformatics, empowering researchers to unravel the complexity of immune responses across the phylogenetic spectrum.
Key output formats and their biological interpretations
MiXCR is a comprehensive computational toolkit for the high-throughput sequencing analysis of T-cell and B-cell receptor repertoires. It processes raw sequencing data to identify and quantify unique immune receptor sequences, providing researchers with detailed insights into adaptive immune responses [20]. The software supports various data types including bulk sequencing (with or without UMIs), single-cell sequencing, and RNA-Seq data, making it applicable to diverse experimental designs in immunology research, vaccine development, and cancer immunotherapy [20] [3].
The extreme diversity of the immune repertoire, theoretically spanning 10¹⁵ to 10²⁰ unique receptors, presents significant analytical challenges [21] [22]. MiXCR addresses this complexity through specialized algorithms for alignment, error correction, and clonotype assembly, enabling researchers to profile immune status from limited biological samples [3]. This protocol focuses on the key output formats generated by MiXCR and their biological interpretation within computational immunology studies.
MiXCR analysis workflow
The MiXCR analysis process consists of two main components: upstream processing of raw sequencing data and downstream analysis of assembled repertoire data [3]. The upstream analysis involves alignment against reference gene databases, barcode processing, error correction, and clonotype assembly, while downstream analysis focuses on comparative repertoire statistics, diversity calculations, and visualization [20] [3].
Workflow visualization
Figure 1: Comprehensive MiXCR analysis workflow showing the sequence of key processing steps from raw sequencing data to downstream analysis.
Experimental protocol for MiXCR analysis
Sample Preparation and Sequencing:
- Starting Material: Use either RNA or DNA as starting material. RNA provides information on expression levels while DNA offers more straightforward clonal quantification [22].
- Library Preparation: Employ targeted amplification protocols such as the QIAseq Immune Repertoire RNA Library Kit, which uses gene-specific primers targeting constant regions and molecular indexing (UMIs) for accurate clonotype assessment [11].
- Sequencing: Perform sequencing on Illumina platforms (e.g., NextSeq500) with appropriate cycle configuration (e.g., 261 cycles for read 1 and 41 cycles for read 2 for TCR analysis) [11].
Data Processing:
- Upstream Analysis: Execute the MiXCR
analyzecommand with the appropriate preset for your protocol. For example:mixcr analyze qiagen-human-rna-tcr-umi-qiaseq input_R1.fastq.gz input_R2.fastq.gz output_prefix[11]. - Downstream Analysis: Utilize MiXCR's post-analysis functions to calculate diversity metrics, repertoire overlap, and generate publication-quality visualizations [20] [3].
Quality Control:
- Review the generated
.reportfiles for alignment rates and clonotype assembly statistics. - Examine UMI/cell barcode distribution plots to identify potential technical artifacts [9].
Key output formats and biological interpretations
Primary output files
Figure 2: MiXCR output file relationships showing the flow from intermediate processing files to final analyzable formats.
Table 1: MiXCR primary output file formats and their applications
| File Format | Content | Biological Application | File Type |
|---|---|---|---|
.vdjca |
Raw alignments against V/D/J/C reference genes | Intermediate file for troubleshooting alignment issues | Binary |
.refined.vdjca |
Alignments with corrected barcode sequences | Quality control of UMI/cell barcode processing | Binary |
.clns |
Assembled clonotypes for all chains | Primary file for downstream analysis | Binary |
.clonotypes.TRB.tsv |
Tab-delimited TRB CDR3 clonotypes | Analysis of T-cell receptor beta chain diversity | Text |
.clonotypes.TRA.tsv |
Tab-delimited TRA CDR3 clonotypes | Analysis of T-cell receptor alpha chain diversity | Text |
.clonotypes.IGH.tsv |
Tab-delimited IGH clonotypes | Analysis of B-cell receptor heavy chain diversity | Text |
.report |
Quality control metrics | Assessment of data quality and protocol efficiency | Text |
Biological interpretation of clonotype table content
The exported clonotype tables (.tsv files) contain exhaustive information about each identified clone, providing the fundamental data for immune repertoire interpretation [11] [3].
Table 2: Key fields in MiXCR clonotype tables and their biological significance
| Field | Description | Biological Interpretation |
|---|---|---|
cloneId |
Unique identifier for each clonotype | Allows tracking of specific clones across samples |
cloneCount |
Number of sequencing reads for the clonotype | Proxy for clonal abundance in the repertoire |
cloneFraction |
Proportion of the repertoire occupied by the clonotype | Quantitative measure of clonal expansion |
uniqueTagCountUMI |
Number of unique UMIs for the clonotype | Accurate molecular count correcting for PCR amplification bias |
aaSeqCDR3 |
Amino acid sequence of the CDR3 region | Determines antigen recognition specificity |
nSeqCDR3 |
Nucleotide sequence of the CDR3 region | Enables tracking of clonal lineages through shared nucleotide motifs |
allVHitsWithScore |
Assigned V gene with alignment score | Reveals genetic elements contributing to receptor formation |
allJHitsWithScore |
Assigned J gene with alignment score | Completes genetic characterization of the receptor |
allDHitsWithScore |
Assigned D gene with alignment score (TRB/IGH only) | Specific to beta chains and antibody heavy chains |
minQualCDR3 |
Minimum quality score in CDR3 region | Quality control for sequence reliability |
Diversity metrics and their biological relevance
The diversity of T-cell repertoires takes into account both the number of unique TCR sequences (richness) and the relative abundance of these sequences (evenness) [21]. Different diversity indices highlight various aspects of the underlying clonal distribution, each with specific biological interpretations.
Table 3: Immune repertoire diversity metrics and their applications
| Metric | Calculation | Biological Interpretation | Application Context |
|---|---|---|---|
| Shannon Index | Accounts for richness and evenness | High values indicate diverse repertoire; sensitive to low-frequency clones | General repertoire health assessment |
| Inverse Simpson Index | Emphasizes dominant clones | Low values indicate oligoclonality (enrichment of specific T-cell clones) | Identification of antigen-driven expansions |
| Gini Coefficient | Measures inequality in frequency distribution (0-1 scale) | 0 = perfect equality; 1 = total inequality (oligoclonality) | Monitoring immune reconstitution |
| DE50 Score | Number of unique clones comprising 50% of in-frame reads | Low values indicate high clonality | Cancer immunotherapy response |
| Morisita-Horn Index | Overlap accounting for shared clone abundance (0-1 scale) | 1 = complete overlap; 0 = no overlap | Longitudinal studies of repertoire stability |
| Jaccard Index | Size of intersection divided by union of clone sets | Similarity measure ignoring abundance | Comparing repertoire publicness between individuals |
Essential research reagents and solutions
Table 4: Key research reagents and computational resources for immune repertoire studies
| Resource | Function | Example Products/Tools |
|---|---|---|
| Library Prep Kits | Target enrichment for immune receptor sequences | QIAseq Immune Repertoire RNA Library Kit (QIAGEN) [11] |
| Reference Databases | Germline gene sequences for alignment | IMGT, MiXCR built-in curated library [3] |
| Analysis Software | Processing and interpreting repertoire data | MiXCR, TRUST4, IgBLAST, IMGT/HighV-QUEST [23] |
| Visualization Tools | Creating publication-quality figures | Platforma (no-code bioinformatics platform) [3] |
| Validation Assays | Functional confirmation of specificities | Tetramer staining, functional assays [24] |
Downstream analysis workflow for repertoire data
Figure 3: Downstream analysis workflow showing key computational approaches for extracting biological insights from clonotype data.
Protocol for diversity and overlap analysis
Diversity Calculation:
- Use MiXCR's
exportClonesfunction with the--diversityparameter to compute multiple diversity indices simultaneously. - Apply the Gini coefficient to detect oligoclonality in cancer or immunodeficient patients [21].
- Utilize the Shannon index to assess general repertoire diversity in vaccine studies [21].
Repertoire Overlap Analysis:
- Calculate the Morisita-Horn index to compare samples from different time points in longitudinal studies.
- Use the Jaccard index to assess publicness of responses across individuals exposed to the same antigen [21].
- Implement statistical testing to determine significance of observed overlaps versus random expectation.
Visualization:
- Generate vector plots (.svg/.pdf) for publication-ready figures of diversity metrics and VJ usage [20].
- Create clonal abundance rank curves to visualize repertoire architecture.
- Plot circos diagrams to illustrate shared clonotypes between samples.
MiXCR provides a comprehensive suite of output formats that enable deep biological interpretation of immune repertoire data. The binary intermediate files (.vdjca, .clns) ensure efficient processing of large datasets, while the exported tabular formats (.tsv) offer rich biological information for downstream analysis. Proper interpretation of these outputs requires understanding both the technical metrics (e.g., cloneCount, uniqueTagCountUMI) and biological context (e.g., diversity indices, clonal expansion).
The integration of these analytical approaches with appropriate experimental designs—such as longitudinal sampling after vaccination or immune challenge—enables researchers to decode the complex patterns embedded in immune repertoires [24]. This provides powerful insights into immune status, disease mechanisms, and therapeutic responses, advancing both basic immunology research and clinical applications in immunotherapy.
Practical Implementation: MiXCR Workflows for Different Experimental Designs
License acquisition and activation
MiXCR is free for academic use but requires a license. For-profit companies require a payable business license [25].
Step-by-Step License Activation:
- Obtain License: Academic users can quickly get a free license at https://platforma.bio/getlicense [26].
- Activate License: Run the following command and paste the license key when prompted [26]:
- Alternative Activation Methods: The license can also be activated by creating a
mi.licensefile in your home directory or the MiXCR installation folder, or by setting theMI_LICENSEenvironment variable to the license key content [26] [20]. - Offline Use: For environments with restricted internet access, whitelist the specific MiXCR IP addresses (e.g.,
75.2.96.100) in your firewall to allow for periodic license validation [26].
Installation protocols
MiXCR requires Java 1.8 or higher to be installed on your system [9] [27]. The following protocols detail the installation process for different operating systems and package managers.
Manual installation (Linux/macOS)
This method provides direct control over the installation location and version [28].
- Create a dedicated directory and navigate into it:
- Download the latest MiXCR release from GitHub. The following command uses version 4.3.2 as an example:
- Unzip the downloaded archive:
- Verify the installation by checking the version:
- Add MiXCR to your
$PATHfor system-wide access. Replace/home/user/mixcrwith the actual path obtained by runningpwdin the MiXCR directory: To make this change permanent, add the export command to your~/.bashrcfile [28].
Installation via package managers
For simplified installation and updates, use a package manager.
- Using Homebrew (macOS/Linux):
Installation on Windows
Windows does not have a dedicated installer, but MiXCR can be run directly from the JAR file [28] [27].
- Download the latest zip archive from the MiXCR GitHub page [28].
- Unpack it into a directory of your choice (e.g.,
C:\mixcr\) [28]. - Run MiXCR from the command terminal using Java:
Essential research reagents and computing solutions
Table 3: Key research reagents and computational tools for immune repertoire analysis with MiXCR.
| Item | Function / Role | Example / Note |
|---|---|---|
| Raw Sequencing Data | The starting input for the MiXCR pipeline. | FASTQ files from 10x Genomics, QIAseq, etc. [9] [11]. |
| Reference Gene Library | Database of V/D/J/C gene segments for alignment. | MiXCR has a curated built-in library; supports IMGT or custom libraries [3]. |
| Java Runtime Environment (JRE) | Required execution environment for MiXCR. | Version 1.8 or higher is required [9] [27]. |
| Unique Molecular Identifiers (UMIs) | Short nucleotide barcodes for error correction. | Allows PCR/sequencing error correction and accurate quantification [3]. |
| Sample Barcodes (Indices) | Used to multiplex multiple samples in a single run. | MiXCR can de-multiplex samples using regex-like patterns [3]. |
Experimental workflow for initial data processing
The following diagram illustrates the logical workflow for installing MiXCR, obtaining a license, and running a standard analysis preset on raw sequencing data.
Protocol for a standard analysis run
MiXCR simplifies analysis through the use of protocol-specific presets. The following command demonstrates a standard analysis for 10x Genomics single-cell V(D)J data, which automatically executes multiple steps including alignment, UMI-based error correction, and clonotype assembly [9] [3].
bash
mixcr analyze 10x-sc-xcr-vdj \
--species hsa \
sample_R1.fastq.gz \
sample_R2.fastq.gz \
results_output
[9]
Protocol-specific presets for 10x Genomics, QIAseq, and other common platforms
Immune repertoire sequencing has become an indispensable tool for researchers and drug development professionals studying the adaptive immune system. The analysis of B-cell and T-cell receptor repertoires provides critical insights into immune responses across diverse contexts, including infectious diseases, autoimmunity, and cancer immunotherapy. However, the complexity of immunosequencing data, coupled with the diversity of wet-lab library preparation protocols, presents significant computational challenges. MiXCR addresses these challenges through its sophisticated system of protocol-specific presets—pre-configured analysis pipelines optimized for particular commercial kits and data types. These presets encapsulate optimized parameters for different library structures, barcode configurations, and sequencing technologies, ensuring high accuracy and analytical consistency while significantly reducing the bioinformatics overhead required for robust immune repertoire analysis [9] [3]. This application note details the implementation, performance, and practical application of these presets within the broader context of computational pipelines for immune repertoire research.
MiXCR provides an extensive collection of built-in presets optimized for a wide range of commercially available immune profiling kits and sequencing platforms. The table below summarizes key presets relevant to major providers:
Table 1: Protocol-Specific Presets in MiXCR for Common Platforms
| Supplier | Preset Name | Species | Data Type | Key Features |
|---|---|---|---|---|
| 10x Genomics | 10x-sc-xcr-vdj [4] |
Any (--species required) |
Single-cell V(D)J | Analyzes full-length V(D)J sequences for paired BCR/TCR from single cells [9] |
| 10x Genomics | 10x-sc-5gex [4] |
Any (--species required) |
Single-cell 5' Gene Expression | Extracts TCR/BCR repertoires from non-enriched single-cell 5' RNA-seq data [4] |
| Qiagen | qiagen-human-rna-tcr-umi-qiaseq [11] |
Human, Mouse | Amplicon TCR | Designed for QIAseq Immune Repertoire RNA Library Kit; UMI-based error correction [11] |
| MiLaboratories | milab-human-rna-tcr-umi-multiplex [4] |
Human | Amplicon TCR | Obtains TCR alpha and beta CDR3 repertoires with high sensitivity and UMI-based accuracy [4] |
| New England BioLabs | neb-human-rna-xcr-umi-nebnext [4] |
Human, Mouse | Amplicon BCR & TCR | Sequences full-length immune repertoires; profiles somatic mutations and isotypes [4] |
| Cellecta | cellecta-human-rna-xcr-umi-drivermap-air [4] |
Human | Amplicon TCR & BCR | Specifically amplifies only functional CDR3 RNA molecules, avoiding non-functional pseudogenes [4] |
| Takara Bio | takara-human-bcr-full-length [29] |
Human, Mouse | Amplicon BCR | For SMART-Seq Human BCR kit; analyzes full-length molecular-barcoded data [29] |
These presets are dynamically updated to accommodate evolving kit chemistries and sequencing technologies. For instance, version-specific presets exist for kits like Cellecta's DriverMap AIR (V2) [4]. This comprehensive coverage ensures that researchers can maintain methodological consistency across projects while leveraging the latest analytical improvements.
Detailed experimental protocols
Protocol 1: Analysis of 10x Genomics single-cell V(D)J data
Purpose: To reconstruct paired T-cell receptor or B-cell receptor sequences from single cells using 10x Genomics Chromium Single Cell Immune Profiling data [9] [4].
Methodology:
- Input Data Requirements: Raw paired-end FASTQ files from 10x Genomics 5' V(D)J libraries (e.g., GEM-X v3 chemistry) [9].
- Preset Command Execution:
The
--speciesflag (e.g.,hsafor Homo sapiens) is mandatory [4]. - Workflow Steps: The preset executes a sophisticated multi-stage pipeline:
- Upstream Analysis: Assembles longer consensus sequences from short reads, aligns to reference V(D)J genes, performs UMI-based error correction, filters cross-cell contamination, and assembles full-length clonotypes with chain pairing refinement [9].
- Quality Control: Generates comprehensive QC reports and plots including percent alignment, chain usage, and UMI/cell barcode distributions [9].
- Output Generation: Produces a set of files including binary alignment files (
*.vdjca), clonotype tables (*.clns), and exported text files with detailed clonotype information for downstream analysis [9].
Protocol 2: Analysis of QIAseq immune repertoire RNA data
Purpose: To process TCR cDNA libraries obtained with the QIAseq Immune Repertoire RNA Library Kit, utilizing UMIs for accurate clonotype quantification [11].
Methodology:
- Input Data Specifications: Paired-end FASTQ files where Read 2 (R2) contains the 12-basepair UMI at its beginning [11].
- Preset Command Execution:
- Output Files: The analysis generates:
mice_tumor_1.report: Human-readable QC reportmice_tumor_1.vdjca: Binary file containing raw alignmentsmice_tumor_1.refined.vdjca: Alignments with refined UMI barcodesmice_tumor_1.clns: TRA/TRB CDR3 clonotypes in binary formatmice_tumor_1.clonotypes.TRA.tsvandmice_tumor_1.clonotypes.TRB.tsv: Exported tab-delimited clonotype tables containing exhaustive information about each clonotype, including CDR3 sequences, V/J gene assignments, and UMI counts [11].
Core MiXCR computational workflow
The analytical process for immune repertoire data in MiXCR follows a logical progression from raw sequencing data to biological insights. The following diagram illustrates the key stages:
Performance benchmarking and validation
Comparative performance metrics
Independent benchmarking studies demonstrate MiXCR's superior performance compared to other widely used VDJ analysis tools such as TRUST4 and Immcantation [30].
Table 2: Performance Benchmarking of MiXCR Against Other VDJ Analysis Tools
| Performance Metric | MiXCR | TRUST4 | Immcantation |
|---|---|---|---|
| Processing Speed (20M reads) | Fastest (∼6x faster than others) [30] | ~6x slower than MiXCR [30] | ~6x slower than MiXCR [30] |
| Sensitivity (on simulated data with errors) | Highest, consistently outperformed others [30] | Lower than MiXCR [30] | Lower than MiXCR [30] |
| Specificity (hybridoma datasets) | High (correctly identified few clones) [30] | Moderate (∼20x more clones than MiXCR) [30] | Low (100-200x more clones than MiXCR) [30] |
| Functionality Range | Most comprehensive: single-cell, RNA-seq, bulk [30] | Limited compared to MiXCR [30] | Limited compared to MiXCR [30] |
| Species Support | Broad range with built-in references [30] | Limited | Limited |
Accuracy in controlled studies
In analyses of hybridoma cell lines—which are monoclonal and expected to show minimal clonal diversity—MiXCR correctly identified only a small number of clones, reflecting biological reality. In contrast, TRUST4 reported approximately 20 times more clones, while Immcantation detected 100-200 times more clones, indicating substantial false positive rates with these tools [30]. This precision is crucial for drug development applications where accurate clonal quantification can influence therapeutic decision-making.
Implementation guide
The scientist's toolkit
Table 3: Essential Research Reagent Solutions for Immune Repertoire Sequencing
| Item | Function/Application |
|---|---|
| 10x Genomics 5' Gene Expression Kit [31] | Generates full-length, paired V(D)J sequences from individual cells for simultaneous immune profiling and gene expression analysis. |
| QIAseq Immune Repertoire RNA Library Kit [11] | Uses gene-specific primers and UMIs for sensitive TCR/BCR clonotype assessment and diversity analysis from RNA. |
| NEBNext Immune Sequencing Kit [4] | Sequences full-length immune repertoires with UMIs, enabling somatic mutation profiling across all isotypes. |
| DriverMap AIR TCR-BCR Assay [4] | Uses multiplex PCR to specifically amplify functional CDR3 regions, avoiding pseudogenes. |
| MiLaboratories Human TCR RNA Multiplex Kit [4] | Provides high-sensitivity TCR alpha and beta CDR3 repertoires with UMI-based accuracy. |
Computational requirements and setup
MiXCR requires Java 11 and is compatible with all major operating systems [9]. The basic command structure for utilizing protocol presets follows this pattern:
For researchers preferring a no-code solution, MiLaboratories offers Platforma, a bioinformatics platform that enables direct import of MiXCR-preprocessed data for downstream clonotyping, differential expression, and sequence liability prediction through a graphical interface [3].
Protocol-specific presets in MiXCR provide an optimized, standardized framework for immune repertoire analysis across diverse experimental platforms. By encapsulating specialized parameters for kits from 10x Genomics, QIAseq, and other leading providers, these presets deliver exceptional accuracy, unmatched processing speed, and comprehensive functionality as validated in rigorous benchmarking studies [30]. This approach significantly reduces the bioinformatics barrier for immunology researchers and drug development professionals while ensuring analytical reproducibility. The integration of these presets into a cohesive computational pipeline, from upstream alignment to sophisticated downstream analysis, establishes MiXCR as an essential tool for advancing research in adaptive immunity, biomarker discovery, and therapeutic development.
Step-by-step guide to the analyze command with practical examples
The MiXCR analyze command provides a powerful, single-command solution for executing complete upstream analysis pipelines from raw sequencing files to clonotype tables [32]. This command significantly streamlines the computational analysis of adaptive immune receptor repertoires by combining multiple processing steps into a unified workflow optimized for specific data types and experimental protocols. Within the broader context of computational pipelines for immune repertoire analysis, MiXCR stands out for its exceptional speed, accuracy, and comprehensive feature set, having processed over 10 million samples and been cited in more than 1,600 academic papers [9].
The command operates using protocol-specific presets that automatically configure optimized parameters for each step of the analysis pipeline, from alignment to clonotype assembly [32]. These presets incorporate years of methodological refinement and benchmarking, ensuring researchers can achieve reliable, reproducible results without extensive parameter tuning. The analysis of B-cell and T-cell receptor sequencing data is particularly sensitive to variations in parameters and analytical setups, making standardized, reproducible pipelines essential for valid scientific conclusions [33] [34]. The analyze command directly addresses this need by providing pre-configured, validated workflows that enhance reproducibility while maintaining flexibility through extensive customization options.
The following diagram illustrates the complete MiXCR analysis workflow, from raw sequencing data to final repertoire analysis:
This workflow encompasses three major phases of immune repertoire analysis [9] [3]. The upstream analysis (blue nodes) processes raw sequencing data through alignment, error correction, and clonotype assembly steps. The quality control phase (green nodes) generates comprehensive reports and clonotype tables. Finally, downstream analysis (red node) enables advanced investigations including somatic hypermutation trees, diversity measurements, and selection analysis [9]. The entire process can be executed through a single analyze command or run as individual steps for better computational resource utilization [3].
Essential Concepts and Terminology
Available Presets
Table 1: Commonly Used MiXCR Analysis Presets
| Supplier/Protocol | Species | Data Type | Preset Name |
|---|---|---|---|
| 10x Genomics | Any | Single-cell VDJ | 10x-vdj-bcr, 10x-sc-xcr-vdj |
| Takara Bio | Human, Mouse | Amplicon BCR/TCR | takara-human-bcr-full-length |
| Illumina | Human | Amplicon TCR | Specific preset by kit |
| BD | Human, Mouse | Single-cell VDJ | Specific preset by kit |
| Oxford Nanopore | Any | Long-read VDJ | Specific preset by kit |
| Generic | Any | RNA-Seq CDR3 | rnaseq-cdr3 |
| Generic | Any | Amplicon | generic-bcr-amplicon-umi |
MiXCR provides a comprehensive collection of built-in presets optimized for commercially available kits and public protocols [32] [29]. These presets automatically configure the appropriate parameters for each library preparation method, ensuring optimal performance without manual parameter tuning. For 10x Genomics single-cell data, the 10x-sc-xcr-vdj and 10x-sc-xcr-vdj-v3 presets are specifically optimized for the latest chemistries [9]. For full-length human BCR data from Takara Bio kits, the takara-human-bcr-full-length preset provides the recommended configuration [29]. The preset system represents one of MiXCR's most powerful features, encapsulating years of protocol-specific optimization into simple, reusable configurations.
Key Computational Steps
Table 2: Core Steps in MiXCR Upstream Analysis
| Step | Function | Key Algorithms |
|---|---|---|
| Alignment | Aligns reads to V/D/J/C reference database | k-mer seed-and-vote, Needleman-Wunsch, Smith-Waterman |
| Tag Refinement | Corrects errors in barcode sequences | Prefix trees, clustering strategies |
| Partial Assembly | Merges overlapping reads from fragmented data | Alignment-guided assembly |
| CDR3 Extension | Imputes missing CDR3 nucleotides (TCR only) | Germline gene-based extension |
| Clonotype Assembly | Groups sequences into clonotypes | Fuzzy clustering, error correction |
| Contig Assembly | Builds consensus receptor sequences | Alignment-guided consensus |
The computational pipeline implements sophisticated algorithms at each processing stage [3]. The alignment step uses a combination of fast k-mer seed-and-vote approaches followed by more precise Needleman-Wunsch and Smith-Waterman algorithms to handle the challenging task of aligning highly diverse immune receptor sequences to germline gene segments. Tag refinement employs specialized error correction algorithms to address artifacts introduced during PCR and sequencing, which is particularly crucial for unique molecular identifier (UMI) based protocols [34]. The clonotype assembly implements a sophisticated two-layer error correction system that distinguishes true biological variation (such as somatic hypermutations in B-cells) from technical artifacts like PCR and sequencing errors [3].
Experimental Protocols
Basic Command Structure
The fundamental syntax for the analyze command follows this pattern:
Where:
preset_namespecifies the analysis preset optimized for your data typeinput_filespoint to your raw sequencing data (FASTQ, FASTA, BAM, or SAM formats)output_prefixdefines the path and prefix for all output filesoptionsallow customization of species, threading, and other parameters [32]
Protocol 1: Analysis of 10x Genomics Single-Cell V(D)J Data
Purpose: Process 10x Genomics single-cell immune profiling data to identify paired clonotypes (α/β or heavy/light chains) with advanced error correction and multiplet resolution.
Materials:
- Raw FASTQ files from 10x Genomics library (R1 and R2)
- MiXCR software with valid license
- Computational resources (8+ CPU cores, 16+ GB RAM recommended)
Method:
Parameters:
10x-sc-xcr-vdj: Preset optimized for 10x Genomics single-cell V(D)J data--species hsa: Specifies Homo sapiens reference library--threads 8: Uses 8 processing threads for faster computation--force-overwrite: Overwrites existing results (use with caution)
Expected Outputs:
results/sample_10x.clones.tsv- main clonotype tableresults/sample_10x.alignments.txt- alignment reportresults/sample_10x.assembleReports.txt- assembly statistics [9]
Protocol 2: Full-Length BCR Analysis with UMI Error Correction
Purpose: Process full-length B-cell receptor sequencing data with molecular barcodes for advanced PCR and sequencing error correction.
Materials:
- Paired-end FASTQ files from SMART-Seq Human BCR kit
- Sample information table (if multiple samples)
Method:
Parameters:
takara-human-bcr-full-length: Preset for Takara full-length BCR data--split-clones-by C: Separates clonotypes by constant region (isotype)- Lane concatenation: Automatic handling of multiple lanes using
L{{n}}pattern [29]
Expected Outputs:
- Clonotypes stratified by isotype (IgM, IgG, IgA, etc.)
- Error-corrected consensus sequences
- Productivity annotations for each clonotype
Protocol 3: Multi-Sample Analysis with Sample Barcodes
Purpose: Process multiple patient samples simultaneously using sample barcodes embedded in file names or index reads.
Materials:
- Multiple sample FASTQ files
- Sample table in TSV format
Sample Table (sample_table.tsv):
Method:
Parameters:
--sample-table: Defines sample barcode mappings--tag-pattern: Specifies barcode structure using pattern language- File name expansion:
{{a}}_{{R}}.fastq.gzmatches all sample files [35]
Expected Outputs:
- Separate clonotype tables for each sample
- Consolidated QC reports across all samples
- Batch processing efficiency
The Scientist's Toolkit
Table 3: Essential Research Reagent Solutions for Immune Repertoire Analysis
| Reagent/Resource | Function | Example Applications |
|---|---|---|
| 10x Genomics 5' V(D)J Kit | Single-cell immune profiling | Paired α/β or heavy/light chain analysis |
| Takara SMART-Seq BCR Kit | Full-length BCR sequencing | B-cell isotype analysis with UMI correction |
| DriverMap AIR TCR/BCR Spike-in Controls | Quality control standards | Pipeline validation and sensitivity assessment |
| MiXCR Software Suite | Immune repertoire analysis | End-to-end processing from RAW reads to clonotypes |
| IMGT Reference Database | Germline gene reference | V/D/J/C gene segment annotation |
| Platforma No-Code Analysis | Downstream analysis | Clonotyping, differential expression, liability prediction |
The experimental and computational tools listed in Table 3 represent essential resources for robust immune repertoire studies [9] [36] [29]. The 10x Genomics platform enables paired-chain single-cell analysis, which is crucial for understanding complete immune receptor identities. The Takara SMART-Seq kits provide full-length coverage of B-cell receptors, enabling comprehensive analysis of variable regions and isotype determination. Quality control standards, such as the DriverMap spike-in controls, are particularly valuable for validating analytical pipelines and establishing sensitivity thresholds [36]. For researchers without coding expertise, the Platforma bioinformatics platform offers a no-code interface for downstream analysis of MiXCR-processed data, including advanced functionalities like clonotyping, sequence liability prediction, and differential expression analysis [3].
Advanced Configuration Options
Customizing Analysis Steps
The analyze command provides flexibility through mix-in options that modify the preset behavior:
This example adds contig assembly and removes tag refinement from the default workflow, allowing researchers to customize the pipeline for specific experimental needs [32].
Output Configuration
Control report generation and output content:
These options suppress JSON reports, output non-aligned reads for debugging, and use local directories for temporary files [32].
Troubleshooting and Optimization
Performance Optimization
For large datasets, these options significantly improve processing speed:
--threads 16: Utilizes more CPU cores for parallel processing--limit-input 100000000: Processes first 100 million reads for testing--use-local-temp: Avoids network latency for temporary files [32]
Quality Control Verification
Always examine the generated reports to verify data quality:
Key quality metrics include alignment rates (>80% typically expected), clonotype diversity measures, and UMI distribution statistics [9] [3].
The MiXCR analyze command provides an optimized, reproducible solution for immune repertoire analysis that balances ease of use with analytical depth. By leveraging protocol-specific presets and supporting extensive customization, it enables researchers to efficiently process diverse data types while maintaining analytical rigor. The structured workflows and comprehensive documentation support reproducible computational immunology, addressing a critical need in the field as highlighted by recent guidelines for reproducible adaptive immune receptor repertoire analysis [33]. As immune repertoire sequencing continues to evolve toward clinical applications, standardized, validated pipelines like those implemented in MiXCR will play an increasingly important role in ensuring the reliability and interpretability of immune monitoring data.
In the field of immune repertoire analysis, the reconstruction of B cell receptor (BCR) lineage trees and the accurate inference of individual-specific gene alleles represent two advanced capabilities that significantly enhance our understanding of adaptive immune responses. These analyses are crucial for investigating antibody affinity maturation, which occurs through somatic hypermutation (SHM) in germinal centers, where B cells undergo cycles of mutation and selection to produce antibodies with increased antigen affinity [37] [38]. The MiXCR computational pipeline provides integrated tools for these advanced analyses, enabling researchers to move beyond basic clonotype identification to detailed studies of B cell lineage relationships and genetic variation [39] [40]. This protocol details the experimental and computational methods for performing allele inference and SHM lineage tree reconstruction within the broader context of computational pipelines for immune repertoire analysis using MiXCR.
Research Reagent Solutions
Table 1: Essential research reagents and materials for BCR repertoire analysis
| Reagent/Material | Function/Purpose |
|---|---|
| MiLaboratories Human IG RNA Multiplex Kit [39] | cDNA library preparation for BCR repertoire sequencing |
| PBMC samples (from human donors) [39] | Source of B cells for repertoire analysis |
| Ficoll density gradient centrifugation [39] | PBMC isolation from whole blood |
| RNA isolation kits [39] | Extraction of high-quality RNA for library preparation |
| Illumina sequencing platforms [39] [40] | High-throughput sequencing of BCR libraries |
| 10x Genomics Universal 5' Gene Expression kits [9] | Single-cell V(D)J sequencing for full-length paired chains |
| Custom 5'RACE-based protocols [40] | Full-length IGH sequencing utilizing UMIs |
The following diagram illustrates the complete analytical workflow from raw sequencing data to lineage tree reconstruction and allele inference:
Figure 1. Complete analytical workflow for SHM tree reconstruction and allele inference.
Experimental Design and Data Collection
Sample Preparation and Sequencing
For longitudinal BCR repertoire analysis, peripheral blood mononuclear cells (PBMCs) are isolated using Ficoll density gradient centrifugation from multiple time points [39]. RNA is extracted and used for cDNA library preparation with targeted BCR amplification kits such as the MiLaboratories Human IG RNA Multiplex kit or similar platforms [39]. For full-length IGH sequencing, custom 5'RACE-based protocols utilizing Unique Molecular Identifiers (UMIs) are recommended to enable error correction and accurate molecule counting [40]. Sequencing is typically performed on Illumina platforms (HiSeq 2000/2500 or similar) with paired-end reads of sufficient length to cover the entire V(D)J region (e.g., 310 bp paired end) [40].
Experimental Considerations
- Longitudinal Sampling: Collect samples at multiple timepoints to track B cell lineage evolution, particularly following immune challenges such as infection or vaccination [39].
- Biological Replicates: Include technical replicates for each sample to account for technical variability [39].
- Cell Sorting: For advanced studies, consider fluorescence-activated cell sorting (FACS) to isolate specific B cell populations (memory B-cells, plasmablasts, plasma cells) before repertoire sequencing [40].
- Single-Cell vs Bulk Sequencing: Choose appropriate sequencing approaches based on research questions—single-cell methods preserve native chain pairing while bulk sequencing provides greater depth for detecting rare clones [9].
Computational Methods
Upstream Analysis with MiXCR
The initial processing of raw sequencing data is performed using MiXCR's analyze command with preset configurations optimized for specific library preparation protocols. The following table summarizes key presets and parameters:
Table 2: MiXCR analysis presets for different BCR sequencing protocols
| Protocol Type | Preset Name | Key Parameters | Applications |
|---|---|---|---|
| Commercial BCR kits | milab-human-bcr-multiplex-full-length [39] |
Default parameters for specific kits | Standardized processing |
| 10x Genomics Single Cell | 10x-sc-xcr-vdj or 10x-sc-xcr-vdj-v3 [9] |
Cell barcode processing | Single-cell BCR analysis |
| Full-length with UMIs | generic-bcr-amplicon-umi [40] |
--tag-pattern for UMI/C-primer extraction |
UMI-based error correction |
| RNA-Seq data | rnaseq-cdr3 [3] |
CDR3-focused assembly | Transcriptomic data |
Example command for processing UMI-based BCR data:
For processing multiple files efficiently, GNU parallel can be utilized:
Quality Control Assessment
Comprehensive quality control is essential before proceeding to advanced analyses. MiXCR provides built-in QC tools to assess data quality:
Key QC metrics to evaluate include:
- Alignment rates: >90% of reads should successfully align to reference gene segments [39]
- Sequencing depth: Minimum of one million sequencing reads per sample [39]
- UMI coverage: Bimodal distribution with clear separation between low-coverage (potentially erroneous) and high-coverage (genuine) UMIs [39]
Allele Inference Algorithm
Individual-specific allele inference is performed using the findAlleles command, which identifies true allelic variants distinguished from somatic hypermutations:
The algorithm employs a sophisticated approach that applies consecutive filters based on:
- Lower diversity bound: Estimated as the number of unique combinations of J and V genes and CDR3-lengths of clonotypes [41]
- Unmutated J and V genes: Utilizing clonotypes with minimal mutations to distinguish alleles from SHM [41]
This approach works effectively even with hypermutated repertoires and requires lower sequencing depth compared to alternative tools [41]. The output includes a personalized reference gene library that is used for subsequent realignment of clonotypes.
Lineage Tree Reconstruction
SHM lineage trees are reconstructed using the findShmTrees command, which groups clones with the same V and J genes and identifies clusters based on shared mutations:
The tree reconstruction algorithm consists of several phases as illustrated below:
Figure 2. SHM lineage tree reconstruction algorithm workflow.
Key algorithm parameters that can be tuned for optimal tree building include:
Table 3: Key parameters for lineage tree reconstruction in MiXCR
| Parameter | Default Value | Function |
|---|---|---|
commonMutationsCountForClustering |
5 | Minimum common mutations to form cluster edges |
maxNDNDistanceForClustering |
1.0 | Maximum NDN mutation penalty per length for clustering |
maxNDNDistanceBetweenRoots |
0.3 | Distance threshold for combining trees |
multiplierForNDNScore |
2.5 | Multiplier for NDN score in distance calculation |
penaltyForReversedMutations |
10 | Penalty multiplied by reversed mutations count |
Data Export and Downstream Analysis
Export lineage trees in human-readable format for downstream analysis:
For downstream analysis in R, load the exported trees and perform specialized analyses such as:
- Tree topology analysis: Quantifying shape properties of lineage trees using tools like MTree [37]
- Selection analysis: Detecting antigen-driven selection using methods like ShazaM [37]
- Mutation pattern analysis: Characterizing SHM patterns in different B cell subpopulations [37]
Example R code for loading and initial analysis:
Applications and Biological Insights
The integration of allele inference and SHM tree reconstruction enables several advanced research applications:
Tracking B Cell Evolution in Immune Responses
Longitudinal SHM tree analysis reveals the dynamics of B cell clone evolution during immune responses. Studies of COVID-19 responses have demonstrated how lineage trees can track the diversification of B cell clones across multiple timepoints following infection [39]. This approach can identify conserved antibody pathways and characterize the development of broadly neutralizing antibodies.
Studying Affinity Maturation Mechanisms
Lineage tree analysis provides insights into fundamental mechanisms of affinity maturation. Recent research has revealed that B cells expressing higher-affinity antibodies may undergo regulated somatic hypermutation, where cells dividing more frequently mutate less per division, protecting high-affinity lineages from accumulating deleterious mutations [38]. This challenges the traditional model of a fixed mutation rate per cell division.
Disease Classification and Biomarker Discovery
Machine learning approaches applied to lineage tree features can distinguish between healthy and disease states. For example, classification models using mutation count outputs from tools like IgTreeZ can differentiate between lineage trees from diffuse large B-cell lymphoma (DLBCL) patients and those from healthy controls [37].
Technical Considerations
Methodological Advantages
The MiXCR approach to lineage tree reconstruction provides several advantages over alternative methods:
- Reference-based alignment: Heavily utilizes alignments with reference segments and known "wild-type" states of V and J regions, unlike algorithms that don't account for underlying sequence structure [42]
- Integrated allele inference: Personalized allele references improve mutation calling accuracy by distinguishing true allelic variants from somatic hypermutations [41]
- Efficient processing: Handles both bulk and single-cell data in a highly compressed, memory-efficient binary format [42]
Limitations and Alternative Approaches
While powerful, these methods have certain limitations:
- Structural variants: Common gene duplications in IG loci can make mapping sequences to specific germline genes challenging [41]
- Low-usage alleles: Alleles with low expression levels may not be detected in AIRR-seq data [41]
- Computational resources: Large datasets may require significant memory and processing power
Alternative tools for specialized analyses include:
- IgTreeZ: Comprehensive Python-based tool for Ig gene lineage tree analysis [37]
- TIgGER: R-based tool for allele inference from hypermutated repertoires [41]
- Partis: Bayesian framework for BCR lineage analysis [41]
The integration of allele inference and somatic hypermutation tree reconstruction within the MiXCR computational pipeline provides researchers with powerful tools for advanced B cell repertoire analysis. These methods enable the detailed investigation of B cell lineage relationships, affinity maturation processes, and the functional consequences of genetic variation in immune receptor genes. The protocols outlined in this application note provide a comprehensive framework for implementing these analyses, from experimental design through computational processing and biological interpretation. As these methods continue to evolve, they will further enhance our understanding of adaptive immune responses in vaccination, infection, and immune-related diseases.
The analysis of adaptive immune receptor repertoires (AIRR) has become increasingly sophisticated, requiring specialized tools for each stage of the analytical pipeline. MiXCR serves as a powerful upstream clonotyping engine that processes raw sequencing data into annotated receptor sequences, while immunarch provides a comprehensive R-based environment for downstream repertoire analysis and visualization [43] [44]. This integration enables researchers to leverage the strengths of both tools: MiXCR's exceptional speed and accuracy in V(D)J alignment and clonotype assembly, coupled with immunarch's extensive statistical and visualization capabilities for biological interpretation [9] [44].
The interoperability between these tools is facilitated by the AIRR Community data standards, which define a common format for sharing immune repertoire data [17] [45]. As immune repertoire sequencing evolves toward multi-modal data integration and larger datasets, robust pipelines that connect specialized tools have become essential for extracting meaningful biological insights [43] [17]. This protocol provides a comprehensive guide for exporting data from MiXCR and preparing it for analysis in immunarch, with additional considerations for other downstream platforms.
MiXCR upstream analysis and export capabilities
MiXCR implements a multi-step upstream analysis pipeline that transforms raw sequencing data into annotated clonotype tables. The workflow consists of alignment against reference V, D, J, and C gene segments; tag refinement for barcode error correction; partial assembly for fragmented data; CDR3 extension for TCR data; clonotype assembly with error correction; and export of final clonotype tables [3]. This sophisticated pipeline enables MiXCR to achieve higher sensitivity and specificity compared to alternative tools, with benchmarking studies showing up to 6-fold faster processing times than Immcantation and significantly fewer false positives than TRUST4 [44].
MiXCR export formats and options
MiXCR provides multiple export options to support different downstream analysis needs, with the AIRR format being particularly important for interoperability with immunarch and other tools [45]. The exportAirr command converts MiXCR's internal alignment (.vdjca) or clonotype (.clna/.clns) files into AIRR-compliant TSV format, which includes standardized column definitions for immune receptor data [45]. Key parameters for this command include --imgt-gaps for IMGT-style gap placement in alignment fields and --from-alignment to extract fields like FWR1, CDR2, and others directly from alignment data [45].
Table: MiXCR Export Formats and Their Applications
| Export Format | Command | Primary Use Case | Key Features |
|---|---|---|---|
| AIRR Standard | exportAirr |
Downstream analysis in immunarch and other AIRR-compliant tools | Standardized column definitions, compatibility with AIRR community tools |
| Default TSV | exportClones |
General analysis and custom pipelines | Customizable column selection, human-readable format |
| Alignment Export | exportAlignments |
Detailed alignment inspection | Includes reference alignment information, mutation details |
For studies requiring specialized germline references, MiXCR supports exporting with IMGT-gapped references using the repseqio utility, which can improve alignment accuracy for certain applications [45]. This is particularly valuable for non-model organisms or populations with underrepresented alleles in standard reference databases [44].
Experimental protocols: from MiXCR export to immunarch analysis
Protocol 1: Basic MiXCR to immunarch workflow
This protocol outlines the complete workflow for processing raw sequencing data through MiXCR and importing the results into immunarch for downstream analysis.
Materials and Reagents:
- Raw sequencing data: FASTQ files from immune repertoire sequencing (bulk or single-cell)
- Computational resources: Server or workstation with adequate memory for dataset size
- Software requirements: MiXCR version 3.0+, R environment, immunarch package [15]
Step-by-Step Procedure:
Process raw data with MiXCR:
Export in AIRR format (if not included in analyze preset):
Prepare metadata file (optional but recommended): Create a tab-delimited metadata file with "Sample" as the first column header followed by experimental variables:
Load data into immunarch:
Perform initial analysis:
Protocol 2: Advanced multi-sample integration
For studies involving multiple samples or time points, proper metadata management and batch processing become crucial for robust downstream analysis.
Materials and Reagents:
- Multiple sample files: MiXCR output files for all samples
- Comprehensive metadata: Sample information, experimental conditions, time points
- Directory structure: Organized folder hierarchy for raw data, processed files, and results
Step-by-Step Procedure:
Organize MiXCR output files: Place all MiXCR clonotype text files (.txt) in a single directory along with a metadata.txt file.
Create comprehensive metadata: Generate a tab-delimited metadata file with the first column named "Sample" containing base names of MiXCR output files without extensions:
Table: Example Metadata Structure for Multi-Sample Analysis
Sample Sex Age Condition Timepoint Treatment Response pt01_pre M 54 CRC 0 None NA pt01_post M 54 CRC 1 Anti-PD-1 Responder pt02_pre F 61 CRC 0 None NA pt02_post F 61 CRC 1 Anti-PD-1 Non-responder Batch loading in immunarch:
Perform comparative analyses:
Research reagent solutions for immune repertoire analysis
Table: Essential Research Reagents and Computational Tools for Immune Repertoire Analysis
| Reagent/Tool | Function | Application Notes |
|---|---|---|
| SMARTer Human TCR α/β Profiling Kit | Template switching for full-length TCR amplification | Used in large-scale studies [46]; ideal for bulk RNA sequencing approaches |
| RNeasy Mini Kit | RNA purification from PBMCs | Maintains RNA integrity for accurate V(D)J sequencing; used in CRC TCR repertoire study [46] |
| 10x Genomics 5' V(D)J Solution | Single-cell immune profiling | Captures paired chains and gene expression; compatible with MiXCR analysis [9] |
| MiXCR Software Suite | V(D)J alignment and clonotype assembly | Provides presets for major platforms; superior speed and accuracy [44] |
| immunarch R Package | Downstream repertoire analysis | Specialized for biomarker discovery and multi-modal data integration [43] |
| AIRR-Compliant References | Standardized germline gene references | Enables cross-study comparisons; critical for reproducible analysis [17] |
Quality control and validation
Robust quality control measures are essential throughout the MiXCR-to-immunarch pipeline to ensure data reliability. For sequencing quality assessment, FastQC and MultiQC provide comprehensive evaluation of raw read quality, sequence length distribution, and base-level accuracy [46]. For clonotype validation, MiXCR generates detailed alignment reports including the percentage of successfully aligned reads, distribution of V/J gene assignments, and error rate estimates [15] [3].
In immunarch, initial data quality can be assessed by examining the basic repertoire statistics and clonal distribution patterns. Unexpected results, such as extreme dominance of single clonotypes or unusual V/J gene usage patterns, may indicate technical artifacts requiring further investigation [43] [15]. The immunarch package includes visualization functions that facilitate rapid quality assessment through diversity metrics, gene usage plots, and clonal space homeostasis curves [43].
Advanced applications and integration scenarios
Multi-modal data integration
The true power of modern immune repertoire analysis emerges from integrating TCR/BCR data with other data modalities. immunarch supports multi-modal immune profiling that combines receptor repertoire data with single-cell expression, spatial transcriptomics, immunogenicity annotations, and clinical metadata [43]. This enables researchers to move beyond simply identifying expanded clonotypes to understanding their functional state, spatial distribution, and clinical relevance.
For example, in oncology applications, integrating TCR repertoire data with tumor transcriptome profiles can identify tumor-reactive T-cell clones and their exhaustion states [17] [46]. Similarly, for B-cell studies, combining BCR sequencing with antigen specificity screening (e.g., LIBRA-seq) enables high-throughput mapping of antibody-antigen relationships [17].
Large-scale data management
As immune repertoire studies scale to hundreds of samples and terabytes of data, efficient data management becomes crucial. immunarch incorporates capabilities for working with datasets that exceed available memory through optimized data structures and processing algorithms [43]. The package can seamlessly handle tens of gigabytes of data without requiring code modifications for server environments [43].
Machine learning and biomarker discovery
The integration of MiXCR and immunarch enables sophisticated machine learning applications for immune repertoire analysis. immunarch provides feature engineering capabilities to build ML-ready feature tables at receptor-, sample-, and cohort-levels, with consistent IDs and metadata for downstream modeling [43]. These features can include diversity metrics, V/J usage patterns, clonality measures, and sequence-based characteristics.
In translational research, this pipeline supports immune biomarker discovery by enabling stratification of patient cohorts, tracking of antigen-annotated clonotypes across timepoints, and identification of repertoire signatures associated with clinical outcomes [43] [46]. For example, in colorectal cancer research, pre-treatment TCR repertoires have shown potential as biomarkers for risk assessment and treatment response prediction [46].
Troubleshooting and optimization
Common challenges in the MiXCR-to-immunarch pipeline include metadata mismatches (solved by verifying sample names in metadata files), format compatibility issues (addressed by using AIRR standard export), and memory limitations with large datasets (mitigated through immunarch's built-in optimizations) [15]. For studies involving highly mutated BCR repertoires, ensuring proper handling of somatic hypermutation during MiXCR alignment and clonal clustering is essential for accurate results [3].
Performance optimization can be achieved through proper resource allocation in MiXCR (adjusting CPU and memory parameters based on data size) and efficient data structures in immunarch [43] [44]. The immunarch development team emphasizes that the package is evolving to handle the increasing scale and complexity of modern immune repertoire data, with version 1.0 introducing significant architectural improvements [43].
This comprehensive integration of MiXCR and immunarch provides researchers with a robust, scalable pipeline for transforming raw sequencing data into biological insights, supporting both basic immunological research and translational applications in biomarker discovery and therapeutic development.
Optimizing Performance: Best Practices and Troubleshooting for MiXCR Pipelines
Immune repertoire analysis, particularly with sophisticated tools like MiXCR, presents significant computational challenges that require strategic management of resources. The process involves aligning raw sequencing data against reference gene libraries and assembling clonotypes, which are computationally intensive steps demanding optimized CPU, memory, and batch processing strategies [3]. Effective resource management is crucial for researchers conducting large-scale analyses, as inefficient allocation can lead to excessive runtimes, failed jobs, or suboptimal hardware utilization. This application note provides detailed protocols and quantitative data to guide researchers in configuring computational environments for efficient MiXCR pipeline execution, framed within the broader context of computational immunology research.
Quantitative Resource Profiling for MiXCR Workflows
Memory and CPU Utilization Across Analysis Stages
Different stages of the MiXCR workflow exhibit varying computational profiles, requiring tailored resource allocation strategies. The alignment phase performs initial mapping of sequencing reads against V-, D-, J-, and C- gene segment databases using specialized algorithms, while clonotype assembly groups alignments through fuzzy matching and clustering with error correction [3]. The following table summarizes resource requirements for key MiXCR operations:
Table 1: Computational Resource Requirements for Key MiXCR Operations
| Processing Stage | Memory Footprint | CPU Utilization | Key Influencing Factors |
|---|---|---|---|
| Alignment | Moderate to High | High (scales with cores) | Reference library size, read length, sequencing depth |
| Tag Refinement | Low to Moderate | Moderate | Barcode complexity, error correction stringency |
| Partial Assembly | Moderate | High | Dataset fragmentation, overlap requirements |
| Clonotype Assembly | High to Very High | High | Clonality, error correction, UMI utilization |
| Export | Low | Low | Export field selection, output format complexity |
Documented cases reveal significant memory consumption variations, with one report indicating unexpected memory usage up to 4TB when using MiXCR v3.0.3 with specific parameters, compared to more typical usage under 12GB in previous versions [47]. This highlights the critical importance of version-specific profiling and parameter optimization.
Hardware Configuration Guidelines
Strategic hardware configuration balances performance requirements with infrastructure constraints. The following table provides hardware recommendations based on dataset scale:
Table 2: Hardware Configuration Guidelines for Different Dataset Scales
| Dataset Scale | Recommended RAM | CPU Cores | Storage Type | Estimated Processing Time |
|---|---|---|---|---|
| Small (<1M reads) | 16-32 GB | 8-16 | SSD | 1-4 hours |
| Medium (1-50M reads) | 32-128 GB | 16-32 | High-performance SSD | 4-24 hours |
| Large (50-200M reads) | 128-512 GB | 32-64 | NVMe/High-speed RAID | 1-5 days |
| Very Large (>200M reads) | 512 GB+ | 64+ | Distributed storage system | 5+ days |
Experimental Protocols for Resource Optimization
Protocol 1: Memory Footprint Reduction
Excessive memory usage represents a common bottleneck in MiXCR analyses. This protocol outlines systematic approaches to identify and mitigate memory constraints:
Initial Configuration Assessment
- Set Java heap size explicitly using
-Xmxand-Xmsparameters (e.g.,-Xmx32Gfor 32GB allocation) - Monitor memory usage throughout execution using tools like
htoportop - Identify peak memory phases to target optimization efforts
- Set Java heap size explicitly using
Parameter Tuning for Memory Efficiency
- Implement the
--not-aligned-R1and--not-aligned-R2parameters to reduce intermediate file sizes - Adjust
--descent-strict-v-region-boundariesto limit alignment search space - Utilize
-OallowPartialAlignments=trueselectively based on data quality requirements [47]
- Implement the
Workflow-Specific Optimizations
- For shotgun analysis: Limit use of
assemblePartialandextendsteps when data quality permits - For single-cell data: Implement stringent barcode filtering to reduce spurious alignments (can eliminate up to 90% of artificial diversity) [3]
- Consider step-by-step execution instead of integrated
analyzecommand for better resource control
- For shotgun analysis: Limit use of
Validation and Quality Control
- Compare pre- and post-optimization results using positive control datasets
- Verify maintained sensitivity through spike-in controls or synthetic sequences
- Document performance metrics for future reference
Protocol 2: CPU Utilization and Parallel Processing
Maximizing CPU efficiency reduces wall-clock time for analysis completion:
Parallelization Strategy
Batch Processing Implementation
- Process multiple samples using MiXCR's file name expansion functionality
- Implement sample barcode assignment directly from file names for efficient metadata handling
- Utilize sample tables for coordinated analysis of multiple patient samples
Performance Monitoring and Adjustment
- Track CPU utilization percentage throughout execution
- Identify underutilized phases for potential optimization
- Adjust thread counts based on specific workflow stage requirements
Protocol 3: HPC and Cloud Deployment
Large-scale analyses often require high-performance computing (HPC) or cloud resources:
HPC Environment Configuration
- Implement appropriate job submission scripts for Slurm or other workload managers
- Configure temporary directory (
--temp-directory) on high-speed local storage - Set appropriate wall-time limits based on dataset scale expectations
Cloud Infrastructure Optimization
- Select instance types balancing CPU, memory, and storage performance
- Implement auto-scaling for batch processing of multiple samples
- Utilize spot instances for cost-sensitive non-time-critical analyses
Data Management Strategy
- Implement staging procedures for efficient data transfer
- Utilize compression for input and output files where appropriate
- Establish systematic naming conventions for output files
Computational Workflow for Immune Repertoire Analysis
The following diagram illustrates the complete MiXCR computational workflow with key decision points for resource management:
MiXCR Computational Workflow
Resource Management Decision Framework
The following decision framework guides researchers in selecting appropriate computational strategies:
Resource Allocation Decision Framework
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Computational Tools for Immune Repertoire Analysis
| Tool/Resource | Function | Application Context |
|---|---|---|
| MiXCR Software Suite | End-to-end analysis of raw sequencing data to clonotype tables | Primary analysis tool for TCR/BCR repertoire data [3] |
| Platforma | No-code bioinformatics platform with MiXCR integration | Downstream analysis, visualization, and interpretation [3] |
| AlignAIR | Deep learning-based sequence alignment | Alternative aligner for complex SHM patterns and allele assignment [48] |
| QIAGEN CLC Genomics | Commercial workflow with immune repertoire module | User-friendly alternative with point-and-click interface [49] |
| GenAIRR Simulation Suite | Synthetic data generation for method validation | Benchmarking, optimization, and pipeline validation [48] |
Effective computational resource management forms the foundation of successful immune repertoire analysis using MiXCR. The protocols and guidelines presented here enable researchers to optimize their analytical workflows while maintaining scientific rigor. As the field advances, emerging technologies like deep learning-based aligners such as AlignAIR offer promising directions for handling complex somatic hypermutation patterns with greater efficiency [48]. Furthermore, institutional initiatives like the Ragon Institute's computational infrastructure project highlight the growing recognition of specialized computational resources as essential components of immunological research [50]. By implementing these resource management strategies, researchers can accelerate discovery while maintaining computational efficiency in their immune repertoire studies.
Quality control (QC) is a foundational step in the computational analysis of adaptive immune repertoires using MiXCR. For researchers and drug development professionals, accurately interpreting QC reports is not merely a procedural formality but a critical determinant of data reliability and subsequent biological conclusions. The MiXCR platform generates comprehensive QC outputs during its analysis of raw sequencing data from technologies like 10x Genomics' single-cell V(D)J solutions [9]. These reports provide diagnostic metrics that allow scientists to identify potential issues stemming from library preparation, sequencing depth, or sample quality, enabling informed decisions about downstream analytical validity. Within the broader context of computational pipeline evaluation for immune repertoire research, mastering MiXCR's QC interpretation ensures that clonal diversity measurements, somatic hypermutation analyses, and other advanced immunological assessments rest upon a verified foundation of high-quality data.
The MiXCR workflow systematically generates QC information at multiple stages. Following upstream analysis, which includes contig assembly, alignment to reference gene databases, and sophisticated error correction, MiXCR produces both text-based summaries and visual plots that collectively assess sample quality [9]. These outputs include metrics such as percent alignment to V(D)J reference genes, chain usage distribution, and unique molecular identifier (UMI) per cell barcode distributions, which are indispensable for identifying technical artifacts that could masquerade as biological signals [9]. For drug development applications, where reproducibility and accuracy are paramount, rigorous QC interpretation provides the necessary groundwork for validating repertoire-based biomarkers or therapeutic responses.
MiXCR Analysis Workflow and QC Integration
The MiXCR analytical pathway comprises three principal phases, with quality assessment deeply integrated throughout the process. Understanding how QC functions within this workflow is essential for proper interpretation and issue identification.
Figure 1.: MiXCR analytical workflow with integrated quality control checkpoints. The pathway begins with raw sequencing data and progresses through sequential analytical steps, culminating in comprehensive QC reporting that informs downstream interpretive analysis.
Upstream Analysis Phase
The upstream analysis phase transforms raw sequencing data into assembled clonotypes through multiple processing stages [3]. The initial alignment phase utilizes a highly efficient k-mer seed-and-vote approach followed by more computationally intensive algorithms like Needleman-Wunsch and Smith-Waterman to align sequences against reference V-, D-, J-, and C-gene segment databases [3]. For paired-end data, MiXCR merges overlapping mate pairs using sophisticated algorithms capable of overlapping mates with minimal nucleotide overlap. Subsequent tag refinement corrects errors within barcode sequences (including UMIs and cell barcodes) and filters out spurious barcodes arising from PCR artifacts, empty droplets, or chimeric molecules [3]. The clonotype assembly stage then groups alignments by similar nucleotide sequences while applying multiple layers of error correction to distinguish true biological variation from technical artifacts [3].
QC Reporting Phase
Following upstream processing, MiXCR generates comprehensive QC reports in both textual and visual formats [9]. These reports provide diagnostic metrics including percent alignment rates, chain usage distributions, and UMI/cell barcode distributions that enable researchers to assess data quality and identify potential issues before proceeding to interpretive analysis [9]. The alignment rates indicate how effectively sequences mapped to immune receptor genes, while chain distributions reveal potential biases in receptor representation. UMI and cell barcode distributions help identify issues with sequencing saturation, cell viability, or amplification biases that could compromise quantitative conclusions about clonal diversity and abundance.
Key QC Metrics and Their Interpretation
Systematic interpretation of MiXCR's QC outputs requires understanding specific metrics, their acceptable ranges, and implications of deviations. The following structured data provides a framework for evaluating data quality.
Table 1: Key QC Metrics in MiXCR Reports and Their Interpretation
| QC Metric | Optimal Range | Potential Issues | Impact on Analysis |
|---|---|---|---|
| Percent Alignment | >80% for targeted V(D)J libraries | Low complexity libraries, poor RNA quality, incorrect species reference | Reduced clonotype recovery, biased diversity estimates |
| UMI Distribution per Cell | Even distribution across cells | Over-amplification, cell lysis, empty droplets | Artificial diversity inflation or reduction |
| Chain Usage Balance | Consistent with biology (e.g., αβ T-cells: ~70% TRA, ~30% TRB) | Primer bias, incomplete reverse transcription | Incomplete receptor characterization |
| Reads per UMI | Sufficient for error correction (≥3-5) | Inadequate sequencing depth, PCR duplicates | Reduced error correction efficacy |
| Cell Barcode Filtering | <90% spurious barcodes (platform-dependent) | Cell viability issues, droplet generation problems | Inaccurate cell number estimation |
Advanced Interpretation Guidelines
Beyond these fundamental metrics, experienced researchers should examine specific patterns in QC outputs. For alignment percentages, investigate the distribution of reads across gene segments (V, D, J, C) as imbalances may indicate primer biases in amplicon-based approaches [3]. When examining UMI distributions, consider both the total diversity and the evenness—high diversity with low evenness may suggest amplification biases, while low diversity with high evenness could indicate limited cell numbers or sequencing depth issues. For chain pairing in single-cell data, the ratio of cells with productive pairs versus those with single chains provides insights into cDNA synthesis efficiency, with rates below 50% often indicating suboptimal reverse transcription or cell integrity problems [9].
In B-cell receptor analyses, the distribution of mutations across sequences provides crucial QC insights; an unexpectedly low mutation rate in memory B-cells or an unusually high rate in naïve B-cells may indicate issues with consensus assembly or contamination between cell populations [18]. Recent MiXCR versions (v4.7.0) have enhanced assembly algorithms that specifically improve robustness against expression level differences between TCR/IG chains, which directly impacts chain balance metrics [18].
Experimental Protocols for QC Assessment
Protocol 1: Comprehensive QC Evaluation of Single-Cell V(D)J Data
This protocol details the steps for generating and interpreting quality control metrics from 10x Genomics single-cell V(D)J data using MiXCR, with an emphasis on issue identification.
Materials Required:
- Raw FASTQ files from 10x Genomics V(D)J libraries
- MiXCR installation (version 4.7.0 or higher recommended)
- Reference genome for target species
- Computational resources meeting MiXCR requirements
Procedure:
- Execute MiXCR Analysis: Run the appropriate MiXCR preset command for your data type. For 10x Genomics 5' V(D)J data with the latest GEM-X chemistry, use:
mixcr analyze 10x-sc-xcr-vdj-v3 --species hsa sample_R1.fastq.gz sample_R2.fastq.gz output_prefix[9]
Generate QC Reports: The
analyzecommand automatically executes the complete workflow, including alignment, assembly, and QC report generation. To specifically export QC plots after analysis, use:mixcr exportPlots --format pdf qc_output[9]Interpret Text Reports: Examine the alignment report for overall mapping rates and gene usage statistics. Species-specific alignment rates below 70% may indicate contamination or incorrect species specification.
Analyze Visual Plots: Evaluate the UMI per cell barcode distribution plot. A bimodal distribution often indicates a mixture of true cells and empty droplets, requiring barcode filtering adjustment.
Validate Chain Pairing: For single-cell data, verify the proportion of cells with paired chains matches expectations (typically >50% for healthy samples). Lower rates may indicate cellular stress or technical issues.
Check Error Correction Efficacy: Review the clustering reports for PCR and sequencing error correction. Abnormally high error rates may suggest issues with library preparation or sequencing chemistry.
Protocol 2: Multi-Sample QC Comparison Using Sample Tables
For studies involving multiple patients or conditions, MiXCR's sample table functionality enables centralized QC assessment across datasets, facilitating batch effect identification.
Materials Required:
- Multiple sample FASTQ files with appropriate barcoding
- Sample table in TSV format
- MiXCR with multi-sample processing capability
Procedure:
- Create Sample Table: Generate a sample table in TSV format specifying sample names and barcode patterns. The structure should include columns for Sample, TagPattern, and relevant barcode tags (e.g., SAMPLE0I1, SAMPLE0I2) [35].
Execute Multi-Sample Analysis: Run MiXCR with the sample table specification:
mixcr analyze --sample-table sample_table.tsv 10x-sc-xcr-vdj-v3 input_R1.fastq.gz input_R2.fastq.gz output[35]Generate Comparative QC: MiXCR will produce aggregated QC metrics across all samples. Examine inter-sample variability in alignment rates, with coefficients of variation >15% suggesting batch effects.
Identify Outlier Samples: Flag samples with alignment rates >2 standard deviations from the mean for further investigation or exclusion.
Assess Technical Reproducibility: For replicate samples, evaluate consistency in UMI distributions and chain usage patterns. High variability may indicate technical noise overwhelming biological signals.
Troubleshooting Common QC Issues
When QC metrics deviate from expected ranges, systematic troubleshooting identifies root causes and informs remediation strategies.
Table 2: Troubleshooting Guide for Common MiXCR QC Issues
| QC Issue | Possible Causes | Investigation Steps | Remediation Approaches |
|---|---|---|---|
| Low Alignment Rate | Wrong species reference; Degraded RNA; Library contamination | Check reference species; Evaluate RNA integrity number; Inspate sequence quality scores | Specify correct --species; Reprepare library from intact RNA; Apply quality trimming |
| Skewed Chain Representation | Primer bias; Amplification issues; Biological anomaly | Compare with expected biological ratios; Check primer sequences in design | Use unique molecular identifiers; Employ multiplex primers; Verify biological context |
| High Spurious Barcode Rate | Cell lysis; Empty droplets; Overloading | Analyze barcode rank plot; Correlate with viability metrics | Adjust cell number input; Optimize droplet generator; Apply stricter barcode filters |
| Uneven UMI Distribution | PCR amplification bias; Inadequate sequencing depth | Examine UMI family size distribution; Calculate saturation metrics | Increase sequencing depth; Optimize PCR cycles; Use UMI-aware normalization |
| Excessive Error Rates | Sequencing chemistry failure; Low template input | Review sequencing provider's QC; Check starting material quantity | Request resequencing; Increase input material; Adjust error correction parameters |
Advanced Troubleshooting Techniques
For persistent QC issues, advanced approaches may be necessary. When encountering consistently low alignment rates despite correct species specification, consider constructing a custom reference library, particularly for non-model organisms or specialized transgenic models [9]. MiXCR supports custom references that can significantly improve alignment for atypical repertoires. For single-cell data with implausibly high cell doublet rates evidenced by unexpected chain pairings (e.g., two full heavy chains in one cell), leverage MiXCR's enhanced algorithms in v4.7.0 that specifically address cross-cell contamination by strictly isolating reads from different cells during assembly [18].
When troubleshooting hypermutation analysis in B-cells, discrepancies between mutation rates calculated by different metrics may indicate issues with germline reference assignment. In such cases, utilize MiXCR's allele inference functionality to improve germline matching, particularly for polymorphic regions [9]. For comprehensive issue resolution across multiple samples, implement the sample table approach to systematically compare QC metrics and identify technical patterns versus biological signals [35].
Table 3: Essential Research Reagent Solutions for MiXCR Immune Repertoire Analysis
| Resource Type | Specific Tool/Reagent | Function in QC Process | Implementation Notes |
|---|---|---|---|
| Wet-Lab Kit | 10x Genomics 5' V(D)J Reagent Kits | Generates single-cell V(D)J libraries with UMIs | Ensures incorporation of cell and molecular barcodes for downstream QC |
| Reference Database | IMGT Reference Database | Provides curated V/D/J/C gene sequences for alignment | MiXCR contains built-in curated library; custom references supported |
| QC Visualization | MiXCR exportPlots functionality | Generates diagnostic plots for alignment and distribution metrics | Integrated into MiXCR workflow; requires no additional coding |
| Multi-Sample Management | MiXCR Sample Tables (TSV format) | Enables batch processing and cross-sample QC comparison | Essential for cohort studies; identifies batch effects |
| Error Correction | MiXCR UMI-aware clustering | Corrects PCR and sequencing errors using molecular barcodes | Critical for accurate diversity estimation; reduces artificial repertoire expansion |
| Contamination Control | MiXCR tag refinement algorithms | Filters spurious barcodes from empty droplets or exploded cells | Particularly important for droplet-based single-cell technologies |
High-throughput sequencing of T- and B-cell receptors enables the in-depth study of the adaptive immune system. However, the data generated is susceptible to inaccuracies introduced during library preparation and sequencing. The polymerase chain reaction (PCR) amplification step can introduce errors as DNA polymerase misincorporates nucleotides, and template switching can create chimeric sequences. Furthermore, the sequencing process itself is not error-free. These PCR and sequencing artifacts artificially inflate the perceived diversity of the immune repertoire, making it difficult to distinguish true, rare clonotypes from technical noise. Accurate computational correction is therefore not merely a preprocessing step but is fundamental for reliable biological interpretation, enabling precise clonotype quantification and diversity assessment [51] [52].
The MiXCR software suite incorporates a sophisticated, multi-layered system designed to identify and correct these artifacts. Its approach is tailored to different data types, including non-barcoded data, data with unique molecular identifiers (UMIs), and single-cell barcoded data. This protocol details the mechanisms and application of these error-correction procedures within the context of a comprehensive computational pipeline for immune repertoire analysis.
Core Error Correction Mechanisms in MiXCR
MiXCR implements a series of sequential error-correction steps that integrate information from sequence quality scores, consensus building, and clustering strategies. The following diagram illustrates the logical workflow and relationship between these core mechanisms.
Multi-Layer Error Correction Workflow
The error correction process in MiXCR involves several key stages, each designed to address a specific category of artifacts [3] [5]:
Alignment and Barcode Extraction: The initial step aligns raw sequencing reads against reference V, D, J, and C gene databases using highly efficient k-mer based algorithms followed by strict Smith-Waterman or Needleman–Wunsch alignment for refinement. For barcoded data, cell and molecular barcode sequences are extracted using a powerful regex-like pattern-matching language at this stage [3].
Tag Refinement for Barcoded Data: This step is crucial for UMI-tagged or single-cell data. It corrects errors within barcode sequences themselves and filters out spurious barcodes originating from exploded cells, empty droplets, or chimeric molecules. The correction algorithm uses prefix trees and clustering strategies, which is vital as spurious barcodes can constitute up to 90% of the data in some protocols [3].
Pre-Clone Assembly: For data containing barcodes (UMIs or cell barcodes), MiXCR aggregates alignments sharing the same barcode value and assembles one or more consensus "pre-clones" using specialized algorithms. This process effectively creates a digital representation of the original source molecule, neutralizing errors introduced in subsequent PCR cycles and sequencing [5].
Quality-Guided Mapping for Sequencing Error Correction: This layer addresses sequencing errors. During core clonotype assembly, reads with low-quality nucleotides in the clonal sequence are deferred. After initial clonotypes are built, these deferred reads are mapped back to the assembled clonotypes using fuzzy matching. If a match is found, the read is rescued and assigned to that clonotype, effectively correcting the sequencing error [5].
Clustering for PCR Error Correction: The final layer corrects PCR errors that may persist even in UMI-barcoded data. A clustering algorithm organizes highly similar clonotypes into hierarchical trees. Within each cluster, clonotypes with significantly smaller counts are attached as "children" to highly similar "parent" clonotypes with greater counts. Only the cluster heads are retained as final, true clones. This strategy efficiently collapses PCR-induced variants back to their original sequence [3] [5].
Key Reagent and Software Solutions
The following table details the essential computational tools and reagents referenced in this protocol, along with their specific functions in the error correction workflow.
Table 1: Research Reagent and Software Solutions for Immune Repertoire Analysis
| Item Name | Type | Function in Error Correction |
|---|---|---|
| MiXCR Software Suite [3] [9] | Analysis Software | Provides the core pipeline for alignment, UMI handling, and multi-layer error correction (quality-guided mapping and PCR clustering). |
| 10x Genomics Single Cell VDJ Kits [4] | Commercial Kit | Generates full-length, paired V(D)J sequences from individual cells. MiXCR's 10x-sc-xcr-vdj preset is optimized for this data. |
| NEBNext Immune Sequencing Kit [4] | Commercial Kit | Provides UMI-tagged, full-length immune gene repertoires. MiXCR's neb-human-rna-xcr-umi-nebnext preset is designed for this kit. |
| MiLaboratories Human Ig/TCR Multiplex Kits [4] | Commercial Kit | Allows UMI-based full-length or CDR3 repertoire sequencing. Dedicated MiXCR presets (e.g., milab-human-rna-ig-umi-multiplex) are available. |
| DriverMap AIR TCR-BCR Profiling [4] | Commercial Kit | Designed for targeted CDR3 amplification. MiXCR provides specific presets (e.g., cellecta-human-rna-xcr-umi-drivermap-air). |
| Platforma [3] | No-Code Platform | Allows execution of MiXCR's analysis and error correction capabilities through a graphical interface without coding. |
Quantitative Assessment of Error Correction
To evaluate the performance and impact of the error correction workflow, it is essential to consult key metrics in the MiXCR reports. The following table summarizes the critical quantitative indicators.
Table 2: Key Quantitative Metrics for Assessing Error Correction in MiXCR
| Metric | Location in Report | Description and Interpretation |
|---|---|---|
| Reads Used in Clonotypes | assemble report |
The percentage of total reads successfully incorporated into final clonotypes. A value >80% typically indicates good data quality and effective correction [53]. |
| Reads Clustered in PCR Error Correction | assemble report |
The percentage of reads merged during the PCR error clustering step. In non-UMI data, this can be 30-40%, which is normal. A very high percentage may indicate excessive PCR duplication [53]. |
| Final Clonotype Count | assemble report |
The total number of distinct clonotypes after all correction steps. A count significantly lower than expected may warrant investigation of other metrics [53]. |
| UMI Output Diversity | refineTagsAndSort report |
The percentage of UMI barcodes retained after correction and filtering. In a good library, a high fraction of UMIs are corrected/dropped, with the remainder carrying most reads (e.g., ~10% of UMIs containing >95% of reads) [53]. |
| Number of Clonotypes per UMI Group | assemble report |
Shows the distribution of consensus sequences per UMI. In high-quality data, >98% of UMI groups should contain a single consensus sequence, with a small fraction (e.g., 1.5%) containing 2-3 due to the "birthday paradox" [53]. |
Detailed Experimental Protocol for Error-Corrected Clonotype Assembly
This section provides a step-by-step protocol for processing a typical UMI-tagged B-cell receptor (BCR) sequencing dataset using MiXCR's built-in presets and error correction functions.
Procedure
Data Input and Preset Selection. Begin with raw paired-end FASTQ files. Use the
analyzecommand with a preset that matches your library preparation kit. The command below is for a MiLaboratories human Ig RNA UMI multiplex kit.- Note: The
--speciesparameter (e.g.,hsafor human) is mandatory. The preset automatically configures the pipeline for optimal alignment, UMI handling, and error correction [4].
- Note: The
Execute the Pipeline. Running the above command initiates the end-to-end workflow, which includes alignment, tag refinement, UMI-based consensus assembly, and clonotype assembly with integrated error correction. No additional parameters are needed for standard use.
Customization of Clonotype Assembly (Optional). If required, the clonotype assembly can be customized. For instance, if the library was sequenced with shorter read lengths and does not cover the full VDJRegion, you can reassemble the results using only the CDR3 region.
- Note: The
assemble-clonotypes-byparameter defines the gene feature used for grouping sequences into clonotypes. The default is often a longer region, butCDR3is a common, shorter alternative [4].
- Note: The
Export Results. Finally, export the corrected clonotype table for downstream analysis. The
exportcommand generates a tab-delimited file with exhaustive information on each clone.- Expected Outcome: The output file (
clones.txt) contains the list of error-corrected clonotypes, including their nucleotide and amino acid sequences, assigned V/D/J genes, and abundance counts [3].
- Expected Outcome: The output file (
Troubleshooting and Quality Control
A critical part of the protocol is verifying the success of the error correction. The following diagram outlines a logical workflow for diagnosing common issues using MiXCR's quality control reports.
Low Alignment Rate: If the percentage of successfully aligned reads is significantly low (<90%), first verify the
--speciesparameter and the chosen analysis preset. Using an amplicon preset for randomly fragmented data (e.g., RNA-Seq) will cause failures. Pre-processing of reads by external tools that reverse-complement sequences can also cause this issue, requiring the-OreadsLayout=Collinearoption during alignment [53].Low Percentage of Reads Used in Clonotypes: A value below 80% after alignment checks may indicate that the defined
assemblingFeature(e.g., full VDJRegion) is longer than what the sequencing reads cover. Re-assemble clonotypes using a shorter feature likeCDR3[53].High UMI Diversity with Multiple Clonotypes: A large percentage of UMI groups containing more than one consensus sequence often indicates low UMI diversity or a wrong tag pattern used during barcode extraction. Verify the wet-lab protocol and the tag pattern specified in the preset [53].
Handling Low-Quality Samples and Cross-Contamination Concerns
In adaptive immune receptor repertoire sequencing (AIRR-seq), the principle of "garbage in, garbage out" profoundly influences data reliability and biological interpretation [13]. Low-quality samples and cross-contamination represent two pervasive challenges that can compromise the integrity of MiXCR-based immune repertoire analysis, potentially leading to erroneous conclusions in research and drug development contexts. These issues manifest through various indicators, including reduced alignment rates, artificial diversity inflation, spurious clonotype detection, and inconsistent sample clustering in downstream analyses [13] [54]. The complex nature of immune repertoire data, characterized by inherent diversity and the need to distinguish true biological variation from technical artifacts, necessitates rigorous quality assessment and contamination control protocols throughout the analytical workflow.
The MiXCR platform incorporates multiple safeguards to address these concerns, but their effectiveness depends on appropriate implementation and informed interpretation of quality metrics [9] [13]. This application note provides a comprehensive framework for identifying, troubleshooting, and mitigating quality issues, specifically tailored for researchers, scientists, and drug development professionals utilizing MiXCR within computational pipelines for immune repertoire analysis.
Early Detection: Pre-Analysis Quality Assessment
Pre-Sequencing Quality Control Checkpoints
Quality control begins prior to sequencing, with critical checkpoints that significantly impact downstream MiXCR analysis outcomes. Sample procurement and preparation protocols must be rigorously standardized, as the timeliness of processing directly affects repertoire stability [55]. Blood samples should be processed within two hours of collection or preserved using specialized preservation tubes if extended storage is unavoidable. Tissue samples require rapid cooling and processing within 30 minutes to prevent nucleic acid degradation [55].
Nucleic acid quality parameters must meet stringent thresholds for successful repertoire sequencing. RNA purity should demonstrate A260/A280 ratios between 1.8-2.2 and A260/A230 ratios greater than 2.0, while RNA integrity numbers (RIN) should be ≥7 to ensure accurate V(D)J gene assembly [55]. Quality assessment should utilize sensitive fluorescence-based quantification (e.g., Qubit) rather than spectrophotometry alone, as the latter may lack specificity for nucleic acid concentration measurement in complex biological samples [55].
Sequencing Quality Evaluation with FastQC
Initial sequencing quality assessment using tools like FastQC provides crucial insights into potential issues affecting MiXCR analysis [56]. Several FastQC modules require special attention when interpreting immune repertoire sequencing data, as certain patterns that would typically flag concerns in other sequencing applications may be expected in AIRR-seq data, while other subtle issues can significantly impact repertoire characterization.
Table 1: Interpreting FastQC Reports for Immune Repertoire Data
| FastQC Module | Expected Patterns in AIRR-Seq | Potential Problem Indicators |
|---|---|---|
| Per Base Sequence Quality | Generally high quality throughout | Quality scores dropping significantly after 185-189 positions in full-length BCR libraries [56] |
| Per Sequence Quality Scores | Right-skewed distribution toward high quality | Distribution skewed toward lower average quality values, even if not flagged by FastQC [56] |
| Per Base Sequence Content | Irregular curves with initial peaks (primers/adapters) | Extreme deviations from expected patterns may indicate library preparation issues [56] |
| Sequence Duplication Level | High duplication levels (red flag common) | Naturally elevated in amplicon libraries; extremely high levels may indicate low input material [56] |
| Overrepresented Sequences | Primers, barcodes, adapters, common V gene segments | Unexpected sequences dominating the library [56] |
The per-base sequence quality assessment is particularly critical, as declining quality toward read ends can compromise the alignment of V(D)J regions in MiXCR [56]. This pattern may result from sequencing-by-synthesis technology limitations, flow cell overloading, or low library diversity [56]. Similarly, a shift toward lower average read quality, even within "passing" thresholds, may indicate that a greater fraction of reads will be discarded during MiXCR's quality filtering steps, potentially reducing effective sequencing depth [56].
MiXCR-Specific Quality Control Metrics and Interpretation
Comprehensive QC Reporting in MiXCR
MiXCR generates exhaustive quality control reports through the mixcr qc command, providing quantitative metrics for every processing step [13]. Proper interpretation of these metrics is essential for identifying specific quality issues and their potential sources. The report presents both overall percentages and qualitative assessments ([OK], [WARN]) for key parameters, enabling rapid evaluation of data quality.
Table 2: Key MiXCR QC Metrics and Their Interpretation
| QC Metric | Optimal Range | Indicators of Problems | Potential Causes |
|---|---|---|---|
| Successfully aligned reads | >85% [57] | Values <85% | Poor sample quality, incorrect species/library specification, severe sequencing issues [13] [57] |
| Reads used in clonotypes | High percentage | [WARN] flag with low percentage | Poor input quality, excessive PCR duplicates, alignment issues [13] |
| Barcode collisions in clonotype assembly | <0.1% [13] | Elevated percentages | Index hopping in sequencing, barcode contamination [13] |
| UMIs artificial diversity eliminated | Context-dependent | High percentages (>30% with [WARN]) [13] | Excessive PCR amplification, UMI sequencing errors [13] |
| Alignments dropped due to low sequence quality | <1% | Elevated percentages | Poor sequencing quality, especially at read ends [56] [13] |
| Overlapped paired-end reads | >90% | Low percentages | Library preparation issues, inappropriate fragment sizing [13] |
The MiXCR workflow incorporates multiple error correction steps that directly address common quality concerns. These include quality-guided mapping to rescue reads with low Phred scores, clustering to correct PCR errors, and sophisticated barcode refinement to eliminate artificial diversity caused by UMI errors [9] [3]. The "UMIs artificial diversity eliminated" metric specifically quantifies how much apparent diversity was removed through UMI error correction, with higher values indicating either excessive PCR amplification or UMI sequencing errors [13].
Visual QC Assessment with Export Functions
Beyond textual reports, MiXCR provides visualization tools that offer complementary insights into data quality. The mixcr exportQc align command generates alignment overview reports across multiple samples, facilitating batch-level quality assessment and identification of outliers [13]. Similarly, mixcr exportQc chainUsage reveals chain distribution patterns that may indicate biological phenomena or technical biases, while mixcr exportQc tags produces barcode coverage statistics particularly valuable for single-cell data [13].
These visualizations help identify issues not immediately apparent in numerical reports. For example, irregular UMI distributions may indicate problems with library quantification or loading, while skewed chain usage patterns might suggest primer bias in multiplex PCR-based libraries [13] [58]. Integration of these visual assessments with numerical QC metrics provides a comprehensive quality evaluation framework.
Addressing Cross-Contamination Concerns
Cross-contamination in AIRR-seq can originate from multiple sources, including sample handling, library preparation, and index hopping during sequencing [58]. The highly multiplexed nature of immune repertoire sequencing makes contamination particularly problematic, as contaminated sequences can be misinterpreted as legitimate, rare clonotypes. MiXCR implements several approaches to detect and mitigate contamination, beginning with barcode collision detection during clonotype assembly [13].
The platform's tag refinement step specifically addresses barcode-associated errors, correcting mistakes in barcode sequences caused by PCR or sequencing errors and filtering out spurious barcodes originating from exploded cells or empty droplets in single-cell protocols [3]. This step is particularly crucial in droplet-based technologies where spurious barcodes can constitute up to 90% of all detected barcodes, significantly inflating apparent diversity if not properly filtered [3].
Strategic Controls and Best Practices
Incorporating appropriate controls represents the most effective strategy for contamination monitoring. The Biological Resources Working Group of the AIRR Community recommends implementing negative controls throughout sample processing and library preparation to detect contamination sources [58]. Additionally, utilizing unique molecular identifiers (UMIs) enables distinction between true biological molecules and amplification artifacts or cross-contamination [54] [58].
Experimental designs should incorporate technical replicates to assess reproducibility, while sample randomization across processing batches helps identify batch-specific contamination issues [58]. For large-scale studies, including synthetic spike-in controls with known sequences provides quantitative assessment of cross-contamination rates and detection sensitivity [58].
Mitigation Strategies: Experimental and Computational Approaches
Integrated Workflow for Quality Assurance
The following workflow diagram illustrates a comprehensive quality management approach integrating both experimental and computational strategies for addressing low-quality samples and cross-contamination concerns throughout the MiXCR analysis pipeline:
This integrated workflow emphasizes proactive quality assessment at multiple checkpoints, with specific thresholds guiding decisions about proceeding to analysis or implementing troubleshooting protocols. The incorporation of UMIs during library preparation is particularly important for both quality control and contamination detection, enabling distinction between biological duplicates and PCR duplicates [54] [58].
Troubleshooting Low-Quality Samples
When quality metrics indicate problems, systematic troubleshooting should address both experimental and computational factors. For samples failing pre-sequencing QC metrics, re-extraction or reprocessing may be necessary, with particular attention to RNA integrity and purity [55]. For samples with poor MiXCR alignment rates, verification of library preparation method compatibility with the selected MiXCR preset is essential, as different protocols (e.g., multiplex PCR vs. RACE-based approaches) require specific analysis parameters [3] [58].
Samples exhibiting high rates of "UMIs artificial diversity eliminated" may benefit from optimization of PCR amplification conditions to reduce duplication rates, while those with elevated barcode collision percentages may require adjustments to library pooling concentrations or implementation of dual-indexing strategies to minimize index hopping [13] [58]. In cases where quality issues persist despite optimization, careful consideration of data interpretation limitations is essential, particularly for diversity estimates and rare clonotype detection.
Essential Research Reagents and Tools
Successful implementation of quality-controlled immune repertoire analysis requires specific reagents and computational tools. The following table summarizes key resources referenced in this application note:
Table 3: Essential Research Reagents and Tools for Quality-Focused Immune Repertoire Analysis
| Category | Specific Product/Tool | Purpose in Quality Management |
|---|---|---|
| Sample Preservation | Streck BCT tubes [55] | Maintain repertoire stability in blood samples during storage |
| RNA Quality Assessment | Agilent Bioanalyzer [55] | Determine RNA Integrity Number (RIN) for input quality control |
| Nucleic Acid Quantification | Qubit Fluorometer [55] | Accurate concentration measurement of extracted nucleic acids |
| Commercial Library Prep Kits | QIAseq Immune Repertoire RNA Library Kit [11], 10X Genomics VDJ kits [9] | Standardized library preparation with UMI incorporation |
| Quality Assessment Tools | FastQC [56] | Pre-alignment sequencing quality evaluation |
| Primary Analysis Software | MiXCR [9] | Immune receptor alignment, error correction, and QC reporting |
| Downstream Analysis | VDJtools [59] | Additional diversity indices and comparative analyses |
These tools collectively enable comprehensive quality monitoring throughout the experimental and computational workflow. Commercial kits offer standardization advantages but require verification of compatibility with specific MiXCR presets [11] [58]. The integration of UMIs is particularly valuable for distinguishing true biological variation from technical artifacts, with MiXCR providing specialized presets for UMI-containing libraries [9] [11].
Robust handling of low-quality samples and cross-contamination concerns is fundamental to generating reliable insights from MiXCR-based immune repertoire analysis. By implementing the comprehensive quality assessment framework outlined in this application note—incorporating pre-sequencing quality control, rigorous interpretation of MiXCR-specific QC metrics, systematic contamination checks, and appropriate troubleshooting protocols—researchers can significantly enhance the reliability of their findings. The integrated experimental and computational approach emphasized throughout this document provides a structured pathway for addressing the pervasive challenges of data quality in immune repertoire studies, ultimately supporting more confident biological interpretations and translational applications in immunology research and drug development.
Advanced parameter tuning for specific research objectives
Within the broader context of computational pipelines for immune repertoire analysis, MiXCR has established itself as a comprehensive solution for profiling T-cell and B-cell receptor repertoires [60]. The software's standard workflows provide robust starting points for common data types, yet the full potential of MiXCR emerges when researchers strategically customize its parameters to address specific experimental designs and research questions [3]. Advanced parameter tuning enables scientists to optimize the utilization of sequencing information, enhance accuracy for particular biological contexts, and extract specialized insights that would otherwise remain inaccessible through default settings alone.
The critical importance of parameter optimization becomes particularly evident when dealing with challenging data sources such as RNA-seq, where false-positive alignments of non-TCR/Ig sequences can substantially compromise data integrity [61]. Similarly, studies focusing on allele inference from repertoire sequencing data require specialized parameter configurations to achieve the ultrasensitive detection necessary for comprehensive allele discovery [62]. This protocol details strategic parameter adjustments across MiXCR's analytical workflow, providing researchers with methodologies to enhance performance for specific research applications including full-length antibody repertoire characterization, allele inference, and analysis of data from non-standard protocols.
Key concepts and terminology
MiXCR operates through a sophisticated multi-step workflow that transforms raw sequencing reads into quantitatively analyzed immune repertoires [3]. Understanding the core concepts and terminology is essential for effective parameter optimization.
The fundamental analytical steps include: (1) alignment of raw sequencing reads against reference V-, D-, J- and C-gene segment databases; (2) tag refinement for error correction in barcode sequences; (3) partial assembly for fragmented data to reconstruct CDR3 regions; (4) CDR3 extension for non-enriched RNA-seq TCR data; (5) clonotype assembly to group sequences by similarity; and (6) contig assembly for reconstructing full-length receptor sequences from fragmented data [3]. A critical concept throughout these steps is the gene feature, which refers to specific regions of the immune receptor genes that can be targeted for alignment or assembly [63]. Commonly used gene features include CDR3, VDJRegion, VTranscript, and VGene, each serving different analytical purposes depending on the experimental design and research objectives.
Table 1: Essential MiXCR Gene Features for Parameter Tuning
| Gene Feature | Application Context | Key Parameter |
|---|---|---|
| VTranscript | 5'RACE protocols, RNA starting material | -OvParameters.geneFeatureToAlign=VTranscript |
| VGene | DNA starting material, protocols preserving 5' V gene regions | -OvParameters.geneFeatureToAlign=VGene |
| VRegion | Multiplex PCR protocols (default) | -OvParameters.geneFeatureToAlign=VRegion |
| VDJRegion | Full-length repertoire analysis | -OassemblingFeatures=VDJRegion |
| CDR3 | Standard clonotype analysis (default) | -OassemblingFeatures=CDR3 |
Another crucial consideration is the selection of appropriate alignment algorithms. MiXCR implements multiple aligners optimized for different biological contexts, with the default linear scorer being particularly suitable for T-cell receptors, while the affine scorer (KAligner2) better handles long indels typical in hypermutated B-cell receptors [63] [3]. The software's preset system provides pre-configured parameter sets optimized for specific library preparation protocols and sequencing technologies, such as 10x-vdj-bcr for 10x Genomics B-cell receptor data or takara-human-bcr-full-length for full-length antibody repertoires [3].
Experimental setup and workflow design
Research reagent solutions
Table 2: Essential Research Reagent Solutions for MiXCR Analysis
| Reagent/Resource | Function/Purpose | Usage Context |
|---|---|---|
| MiXCR Software Suite | Core analysis platform for immune repertoire sequencing data | All analysis workflows; requires Java 11 [9] |
| Reference Gene Library | Built-in V/D/J/C gene segments for alignment | Species-specific alignment; default or custom libraries [3] |
| Unique Molecular Identifiers (UMIs) | Molecular barcodes for error correction and accurate quantification | Full-length repertoire analysis; PCR error correction [63] |
| Platforma Bioinformatics Platform | No-code GUI for interactive analysis and visualization | Researchers without coding expertise [16] |
| IMGT Database | Reference database for immunoglobulin and T cell receptor genes | Custom reference library construction [9] |
Workflow visualization
The following diagram illustrates the comprehensive MiXCR analytical workflow, highlighting key stages where strategic parameter tuning significantly impacts results:
Diagram 1: Comprehensive MiXCR analytical workflow with key parameter tuning points. Strategic adjustments at critical decision points (red diamonds) enable optimization for specific research applications.
Parameter optimization strategies
Alignment stage optimization
The alignment stage represents the most critical phase for parameter optimization, as it fundamentally determines which sequences will be available for subsequent analysis [64]. Strategic adjustments at this stage can dramatically impact both sensitivity and specificity, particularly for challenging data types.
Gene feature specification provides one of the most impactful alignment optimizations. The -OvParameters.geneFeatureToAlign parameter should be carefully matched to both the starting material and library preparation protocol [63]. For RNA starting material with 5'RACE-based amplification, VTranscript enables utilization of information from both reads, particularly 5'UTRs and portions of the coding sequence from reads opposite to CDR3 [63]. Conversely, for DNA starting material with preserved 5' V gene regions (including introns, leader sequences, and 5'UTRs), the VGene option increases sequencing information utilization from the 5' end of the molecule, enhancing V gene identification accuracy [63]. The default VRegion remains suitable for multiplex PCR protocols targeting specific V gene segments [63].
Algorithm selection should be guided by biological context. For B-cell receptor data with expected hypermutations and indels, KAligner2 with affine scoring outperforms the default aligner [63]. This specialized aligner better handles nucleotide-length indels within V gene segments that are characteristic of somatically hypermutated antibody sequences. The alignment algorithm can be specified using the -p parameter (e.g., -p kaligner2).
Boundary parameters require special consideration for RNA-seq data to minimize false alignments. Research indicates that setting -OvParameters.floatingLeftBound=false and -OjParameters.floatingRightBound=false forces global alignment at the sequence ends, significantly improving discrimination between true TCR/Ig alignments and false-positive non-TCR/Ig sequences [61]. This approach extends V-gene alignment to the 5' end and J-gene alignment to the 3' end of sequences, even when doing so reduces the total alignment score.
Assembly and error correction optimization
The assembly phase transforms aligned sequences into quantified clonotypes while implementing sophisticated error correction strategies. Parameter optimization at this stage directly impacts the accuracy of clonotype reconstruction and the effectiveness of PCR/sequencing error discrimination.
Assembly feature selection determines the clonotyping strategy. While the default CDR3-based assembly suffices for most basic applications, full-length repertoire analysis requires specification of -OassemblingFeatures=VDJRegion to capture the complete variable domain [63]. This comprehensive approach enables analysis of all framework regions (FRs) and complementarity-determining regions (CDRs), providing a more complete view of receptor diversity and enabling detection of hypermutations outside the CDR3.
Error correction parameters must balance sensitivity with specificity. For UMI-tagged data, the -OcloneClusteringParameters=null parameter disables frequency-based PCR error correction when UMIs already provide molecular validation [63]. For non-UMI data, the -OclusteringFilter.specificMutationProbability=1E-5 parameter establishes a threshold for distinguishing true hypermutations from PCR errors in B-cell data [63]. Quality filtering can be adjusted using -ObadQualityThreshold to exclude low-quality bases from consensus building, with optimal values dependent on sequencing quality.
Isotype separation in B-cell receptor analysis requires the -OseparateByC=true parameter, which distinguishes clones with different constant regions, enabling class-switch analysis [63]. This capability is particularly valuable for studying immune responses where different antibody isotypes mediate distinct effector functions.
Advanced applications and specialized protocols
Allele inference represents a powerful advanced application of MiXCR, enabled through specialized parameters and analysis modes. The software incorporates a novel algorithm for ultrasensitive V and J gene allele inference from repertoire sequencing data, capable of processing even hypermutated, isotype-switched BCR sequences [62]. This functionality enables high-throughput novel allele discovery from existing datasets and has been validated against long-read genomic sequencing data [62]. Implementation typically involves specialized export parameters and post-processing workflows to generate individual high-quality gene segment libraries.
RNA-seq data optimization requires specific parameter adjustments to address the unique challenges of non-enriched data. Beyond the boundary parameter modifications previously mentioned, RNA-seq analysis benefits from MiXCR's partial assembly algorithm, which rescues alignments that only partially cover the CDR3 region [3]. For TCR data (but not Ig data due to potential hypermutations), the CDR3 extension step imputes missing nucleotides at CDR3 edges using germline reference information, significantly improving yield from non-enriched data [3].
Single-cell data from platforms like 10x Genomics benefits from dedicated presets (mixcr analyze 10x-sc-xcr-vdj or mixcr analyze 10x-sc-xcr-vdj-v3) that automatically optimize parameters for cellular barcode processing, UMI consensus building, and chain pairing refinement [9]. These presets incorporate sophisticated algorithms for filtering spurious barcodes from exploded cells or empty droplets, which can constitute up to 90% of barcodes in some protocols [3].
Validation and quality control
Robust validation and quality control procedures are essential when implementing advanced parameter configurations. MiXCR provides comprehensive reporting capabilities that should be utilized to assess the impact of parameter adjustments on analysis quality.
The --report parameter generates detailed human-readable logs at each processing stage, enabling monitoring of key metrics such as alignment rates, clonotype counts, and error correction efficiency [63]. For alignment, the report includes statistics on successfully aligned reads (typically 65% or higher for quality data), failure reasons (absence of V/J hits, low scores), and overall efficiency [63]. Assembly reports provide information on final clonotype counts, reads utilized, PCR error correction efficacy, and quality-based filtering outcomes [63].
Table 3: Key Quality Control Metrics for Parameter Optimization
| QC Metric | Target Range | Interpretation |
|---|---|---|
| Alignment Success Rate | >65% for quality data | Indicators of library quality and appropriate species reference [63] |
| Reads Used in Clonotypes | >50% of total reads | Measure of data utilization efficiency [63] |
| PCR Error Correction Rate | Variable by protocol | Indicator of PCR duplication level and correction effectiveness [63] |
| False Alignment Rate | Near zero | Critical for RNA-seq data; indicates alignment specificity [61] |
| Clonotype Distribution | Sample-dependent | Should reflect biological expectations; assess overdominant clones |
For RNA-seq analyses specifically, validation should include assessment of false alignment rates using control samples known to have zero TCR/Ig content [61]. MiXCR's rigorous optimization for RNA-seq data has demonstrated negligible false-positive rates across diverse input dataset types when appropriate parameters are employed [61]. Additionally, the software provides specialized QC plot generation capabilities including percent alignment, chain usage, and UMI/cell barcode distribution visualizations that enable multi-sample quality assessment [9].
Benchmarking studies have demonstrated MiXCR's superior performance characteristics, with faster processing speeds, greater sensitivity, and higher accuracy compared to alternative tools like TRUST4 and Immcantation [9]. These performance advantages are maintained across diverse parameter configurations, though optimal settings are protocol-dependent and should be validated using the QC framework outlined above.
Strategic parameter tuning transforms MiXCR from a standardized processing tool into a powerful platform for addressing diverse research objectives in immune repertoire analysis. The key to successful implementation lies in understanding the relationships between experimental designs, biological questions, and corresponding software parameters. By selectively adjusting gene features, alignment algorithms, assembly criteria, and error correction thresholds, researchers can extract nuanced insights from complex immunological datasets that would remain inaccessible through default workflows alone.
The parameter optimization strategies detailed in this protocol enable researchers to enhance analytical sensitivity for challenging data types like RNA-seq, improve accuracy for allele inference studies, and reconstruct full-length antibody repertoires with unprecedented fidelity. As immune repertoire sequencing continues to evolve toward increasingly diverse applications and methodologies, mastery of these advanced parameter tuning approaches will empower researchers to maximize the scientific return from their investigative efforts while maintaining the rigorous quality standards essential for robust immunological research.
Benchmarking MiXCR: Validation, Performance Metrics, and Tool Comparison
The analysis of adaptive immune receptor repertoires (AIRR) has become indispensable for advancing immunology research, vaccine development, and therapeutic discovery. The complex nature of T-cell receptor (TCR) and B-cell receptor (BCR) data, characterized by extensive diversity arising from V(D)J recombination and somatic hypermutation, demands robust computational tools for accurate interpretation [44]. Among the available software solutions, MiXCR, TRUST4, and Immcantation have emerged as prominent platforms for processing VDJ sequencing data. Each offers distinct approaches to tackling the challenges of immune repertoire analysis, with significant implications for data accuracy, computational efficiency, and biological insights. This comparative analysis examines the performance metrics of these three tools through the lens of published benchmarking studies and technical documentation, providing researchers with evidence-based guidance for tool selection within computational immunology pipelines.
The critical importance of choosing appropriate analytical software cannot be overstated, as inaccuracies in the initial clonotyping phase propagate through all subsequent analyses, potentially compromising biological conclusions [44]. Performance variations become particularly pronounced when dealing with the complex error profiles of next-generation sequencing data, the extensive germline diversity of immune genes, and the specific analytical requirements of different experimental designs ranging from bulk sequencing to single-cell applications. By systematically evaluating functionality, processing speed, and accuracy metrics across these platforms, this analysis aims to equip researchers with the necessary information to optimize their immune repertoire studies within the broader context of MiXCR-focused research methodologies.
Functional capabilities and design philosophies
The three tools examined in this analysis approach immune repertoire analysis with distinct design philosophies and functional capabilities that directly influence their application suitability. MiXCR operates as a comprehensive, integrated solution that functions as a "gold standard analytical package" for TCR and immunoglobulin repertoire profiling [65]. Its unified architecture supports a remarkably broad range of data types, from targeted TCR/IG libraries to RNA-Seq and even Exome-Seq data with minimal TCR/IG coverage. This versatility extends to species support, with a uniquely curated built-in reference library that undergoes continuous updates, supplemented by custom reference creation capabilities and automated novel allele discovery [9] [44].
Immcantation adopts a modular, ecosystem-based approach described as a "start-to-finish analytical ecosystem" for high-throughput AIRR-seq datasets [66] [67]. Rather than a single tool, it comprises interconnected Python and R packages that collectively address the entire analytical workflow from raw sequencing reads to advanced population structure and repertoire analysis. This framework emphasizes community standards and interoperability, supporting both the original Change-O standard and the Adaptive Immune Receptor Repertoire (AIRR) standard developed by the AIRR Community. Its strength lies in specialized analytical capabilities for B-cell biology, particularly lineage tree construction, mutation, selection hypothesis testing, and V-D-J haplotype determination through contributed packages like IgPhyML and RAbHIT [67].
TRUST4 positions itself as a specialized solution for "immune repertoire reconstruction from bulk and single-cell RNA-seq data" without requiring targeted enrichment [68]. Its distinguishing capability involves performing de novo assembly on V, D, J, and C genes, including the hypervariable CDR3 region, from standard RNA-sequencing data, making it particularly valuable when targeted immune sequencing is unavailable. TRUST4 supports both single-end and paired-end bulk or single-cell sequencing data with any read length, employing a reference-guided assembly approach that realigns contigs to IMGT reference gene sequences [68]. However, unlike MiXCR's automatically updated references, TRUST4 relies on user-provided references without built-in allele discovery capabilities, which represents a significant functional limitation for studying populations with incomplete germline characterizations [44].
Table 1: Core functional capabilities across platforms
| Feature | MiXCR | TRUST4 | Immcantation |
|---|---|---|---|
| Primary Analysis Type | Bulk & single-cell | Bulk & single-cell RNA-seq | Bulk & single-cell |
| Reference Management | Built-in curated library + allele discovery | User-provided references only | IMGT with manual management |
| Supported Data | Targeted VDJ, RNA-Seq, Exome-Seq | RNA-seq data (non-enriched) | Targeted VDJ sequencing |
| Single-Cell Support | 10x Genomics, Parse, BD Rhapsody | 10x Genomics (via BAM) | Through nf-core/airrflow |
| Key Differentiator | Comprehensive all-in-one solution | No enrichment required | Specialized B-cell analysis |
Performance benchmarking: speed and accuracy
Rigorous performance benchmarking reveals substantial differences in processing speed and analytical accuracy between the three tools, with significant implications for experimental design and resource allocation. In computational efficiency comparisons, MiXCR demonstrates superior processing speed, consistently outperforming both TRUST4 and Immcantation across datasets of varying sizes [30]. In standardized tests processing bulk TCR sequencing data with UMIs, MiXCR completed analysis of a 20-million-read dataset in under 2 hours, while Immcantation required over 10 hours – representing a 6-fold speed advantage for MiXCR [30] [44]. This efficiency differential becomes increasingly pronounced with larger datasets, highlighting MiXCR's particular advantage in large-scale studies where computational time represents a critical consideration.
Analytical accuracy assessments using simulated datasets with known true repertoires further distinguish the platforms. When evaluating sensitivity – defined as the correct identification of exact VDJ sequence matches to true repertoires – MiXCR demonstrated superior performance under both baseline conditions and with introduced sequencing errors [30]. This robust error handling proves particularly valuable for biological datasets where sequencing artifacts are commonplace. In monoclonal hybridoma datasets, where minimal clonal diversity is expected, MiXCR correctly identified only a small number of clones, while TRUST4 reported approximately 20 times more false positives, and Immcantation detected between 100-200 times more clones than MiXCR [30] [44]. This dramatic disparity in specificity underscores how tool selection can fundamentally influence biological interpretations.
For single-cell applications, performance considerations extend beyond traditional speed and accuracy metrics to encompass cell detection efficiency. Both MiXCR and the 10x Genomics Cell Ranger perform comparably in standard conditions, identifying similar numbers of T and B cells with productive receptors [44]. However, MiXCR demonstrates superior robustness with suboptimal data, maintaining significantly higher cell detection rates than Cell Ranger when sequencing depth is reduced to 50% of original reads [44]. TRUST4 shows fundamental limitations in single-cell contexts due to inadequate noise filtration, resulting in reports of approximately 10 times more "cells" that actually represent technological artifacts rather than biological entities [44].
Table 2: Quantitative performance metrics from benchmarking studies
| Performance Metric | MiXCR | TRUST4 | Immcantation |
|---|---|---|---|
| Processing Time (20M reads) | ~2 hours | >2 hours | ~10 hours |
| Relative Speed | 6x faster | Baseline | 5x slower |
| Sensitivity (Baseline) | Highest | Intermediate | Lower |
| Sensitivity (With Errors) | Maintains advantage | Declines | Declines |
| False Positives (Hybridoma) | Minimal (1x) | ~20x higher | 100-200x higher |
| Single-Cell Robustness | High (works with 50% reads) | Low (10x false cells) | Not benchmarked |
Experimental protocols and implementation
MiXCR implementation for bulk and single-cell data
The MiXCR workflow employs a streamlined, preset-based approach that simplifies implementation while maintaining analytical rigor. For standard bulk TCR sequencing analysis, the recommended protocol utilizes the analyze amplicon command with parameters specific to the experimental design [69]:
This command executes a comprehensive workflow including read alignment, UMI-based error correction, clonotype assembly, and export of tabular results. For single-cell data from 10x Genomics experiments, MiXCR provides dedicated presets that optimize parameters for this specific technology [9]:
The MiXCR single-cell workflow incorporates specialized steps for cellular barcode processing, cross-cell contamination removal, and multiplet resolution, generating both clonotype tables and comprehensive quality control reports. The tool automatically generates interactive QC reports including alignment statistics, chain usage distribution, and UMI/cell barcode distributions, enabling rapid assessment of data quality [9].
TRUST4 workflow for RNA-seq-based repertoire reconstruction
TRUST4 operates through a single run-trust4 command that requires careful preparation of reference databases and appropriate parameter specification based on input data type [68]. For bulk RNA-seq data in BAM format, the basic implementation protocol is:
The reference file specified by -f must be generated from the reference genome and annotation GTF file using the provided BuildDatabaseFa.pl script, while the --ref file typically comes from IMGT database downloads [68]. For single-cell RNA-seq data with cellular barcodes, additional parameters must be specified:
TRUST4 outputs multiple files including trust_report.tsv containing CDR3 information, trust_cdr3.out with detailed gene annotations, and trust_airr.tsv in AIRR-compatible format [68].
Immcantation pipeline for comprehensive repertoire analysis
Immcantation employs a modular workflow typically orchestrated through the nf-core/airrflow pipeline, which integrates multiple analytical components [67]. The implementation begins with raw read processing using pRESTO for quality control, primer masking, and assembly. Subsequent steps utilize Change-O for clonotype assignment, gene assignment, and creation of rearrangement databases compatible with the AIRR standard. Advanced population structure analysis is then performed using Alakazam for diversity estimation and SHazaM for mutational analysis [66].
For B-cell repertoire studies, researchers often incorporate IgPhyML for phylogenetic lineage tree construction and selection testing, typically accessed through the Dowser package [67]. This multi-tool approach provides powerful analytical capabilities but requires substantial computational expertise and workflow integration efforts. The framework supports both the original Change-O standard and the newer AIRR Community standard, facilitating data interoperability across different analytical tools [66].
Workflow visualization and decision pathways
The analytical workflows for immune repertoire analysis follow structured pathways with tool-specific optimizations. The following diagrams illustrate the core processing logic for each platform, highlighting key differentiation points in their approaches to data analysis.
MiXCR integrated workflow
MiXCR workflow diagram
TRUST4 assembly-based approach
TRUST4 workflow diagram
Tool selection decision pathway
Tool selection decision pathway
Essential reference databases
Accurate V(D)J annotation fundamentally depends on comprehensive germline reference databases, with significant performance differences observed between tools based on their reference management approaches [44]. The IMGT database serves as the foundational resource for most tools, providing curated V, D, J, and C gene sequences for multiple species. However, IMGT has recognized limitations including slow update cycles, population bias, and incomplete allele coverage that can substantially impact analytical accuracy [44]. Studies demonstrate that using population-matched references with allele discovery capabilities can recover 15-20% more productive sequences compared to static IMGT-only approaches, making this a critical consideration for studies involving non-European populations or rare alleles [44].
MiXCR's built-in curated library with continuous updates and automatic novel allele discovery (findAlleles) represents a significant advantage, particularly for large-scale or multi-species studies where reference completeness directly influences clonotype detection rates [9] [44]. The platform's buildLibrary function further enables custom reference creation for specialized applications. TRUST4 relies exclusively on user-provided references without integrated discovery capabilities, requiring researchers to manually generate reference files using the BuildImgtAnnot.pl and BuildDatabaseFa.pl scripts provided with the software [68]. Immcantation supports reference improvement through the TIgGER package for allele inference but requires manual reference management, presenting a steeper learning curve for implementation [44].
Computational environment specifications
The computational demands of immune repertoire analysis vary significantly between tools, with important implications for resource planning and experimental design. MiXCR requires Java 11 and demonstrates optimized performance across all operating systems, with benchmarking tests typically conducted on servers with 24 CPU cores and 128 GB RAM [30] [9]. The tool's efficient resource utilization enables processing of 20-million-read datasets in approximately 2 hours, with linear scaling supported through adjustable CPU and memory parameters [30] [9].
TRUST4 is implemented in C and depends on pthreads and samtools (which requires zlib), with successful compilation reported on MacOS using gccdarwin17.7.0 and gcc9.2.0 installed via Homebrew [68]. The software is also available through Bioconda and Docker containers, simplifying deployment. Memory requirements are generally moderate but increase substantially with large single-cell datasets due to the de novo assembly approach.
Immcantation presents the most complex computational environment, requiring multiple interconnected R and Python packages typically deployed through Docker containers or the nf-core/airrflow Nextflow pipeline [66] [67]. This approach facilitates reproducibility but demands substantial computational resources, with processing times approximately 5-fold longer than MiXCR for equivalent datasets [30]. The framework's modular design enables distributed processing, but comprehensive B-cell lineage analysis with IgPhyML can require extended computation times for large datasets.
Table 3: Essential research reagents and computational resources
| Resource Category | Specific Requirements | Function in Analysis |
|---|---|---|
| Reference Databases | IMGT database, species-specific references | V/D/J gene annotation accuracy |
| Sequence Data | FASTQ files (targeted or RNA-seq) | Input for repertoire reconstruction |
| Alignment Files | BAM format (for TRUST4) | Coordinate-sorted reads for assembly |
| Species Specification | Human, mouse, custom species | Germline reference selection |
| Computational Resources | 24+ CPU cores, 128GB RAM | Large dataset processing capacity |
| Containerization | Docker, Singularity | Reproducible environment deployment |
The comparative performance analysis of MiXCR, TRUST4, and Immcantation reveals a consistent pattern of trade-offs between computational efficiency, analytical accuracy, and functional specialization. Benchmarking data unequivocally demonstrates MiXCR's superior performance in processing speed, achieving up to 6-fold faster analysis times compared to other tools while maintaining higher sensitivity and specificity across diverse dataset types [30]. This efficiency advantage, combined with comprehensive functionality spanning both bulk and single-cell applications, positions MiXCR as the optimal choice for most standard immune repertoire studies, particularly those prioritizing rapid turnaround or analyzing large sample cohorts.
The critical importance of analytical accuracy emerges strongly from hybridoma dataset evaluations, where MiXCR correctly identified minimal clones while other tools reported dramatic false-positive rates [30] [44]. This precision in clonotype detection proves essential for valid biological interpretations, especially in clinical contexts where false clonal assignments could directly impact diagnostic or therapeutic decisions. MiXCR's integrated error correction mechanisms and sophisticated noise filtration provide tangible advantages in data quality, particularly for challenging samples with complex error profiles or low sequencing depth.
Despite the clear performance advantages of MiXCR for general applications, context-specific tool selection remains important. TRUST4 offers unique value for repertoire analysis from standard RNA-seq data without targeted enrichment, while Immcantation provides specialized capabilities for advanced B-cell biology studies requiring lineage tree construction and selection analysis [68] [67]. As the field progresses toward increasingly integrated multi-omic approaches, tools like scRepertoire that enable seamless combination of V(D)J and transcriptomic data will grow in importance [70]. Future methodology development should prioritize not only analytical performance but also interoperability with emerging machine learning frameworks and standardized data formats to advance the entire field of computational immunology.
Accurate clonotype identification from Adaptive Immune Receptor Repertoire Sequencing (AIRR-seq) data is a cornerstone of immunology research, directly influencing the validity of downstream biological conclusions. The presence of PCR errors, sequencing artifacts, and somatic hypermutations presents a significant challenge, potentially leading to both false-positive clones (reduced specificity) and false-negative clonotypes (reduced sensitivity). This application note details a rigorous framework for validating the sensitivity and specificity of the MiXCR computational pipeline in clone identification, demonstrating its superior performance through controlled benchmarks and practical experimental protocols.
Performance Benchmarking
Comparative Sensitivity Analysis
The sensitivity of MiXCR was quantitatively evaluated against other prominent VDJ analysis tools—Immcantation and TRUST4—using simulated UMI-containing datasets. These datasets were designed with varying clonal abundances and introduced increasing frequencies of sequencing errors to test the robustness of each tool. Sensitivity was calculated as the proportion of true VDJ sequences correctly identified by each tool.
Table 1: Sensitivity Comparison on Simulated Data with Sequencing Errors
| Tool Name | Baseline Sensitivity (0% Error) | Sensitivity with Low Error Rate | Sensitivity with High Error Rate |
|---|---|---|---|
| MiXCR | Highest | Highest | Highest |
| Immcantation | Intermediate | Intermediate | Intermediate |
| TRUST4 | Intermediate | Intermediate | Intermediate |
Under baseline conditions with no introduced errors, MiXCR demonstrated greater sensitivity than the other tools. This performance advantage was maintained as sequencing errors were introduced, with MiXCR consistently outperforming Immcantation and TRUST4 across all error rates [30].
Specificity Assessment via Hybridoma Datasets
Specificity was assessed using datasets derived from hybridoma cell lines. Given the monoclonal origin of these cell lines, a highly specific tool is expected to report only a small number of clones, with minor variations potentially arising from limited somatic hypermutations. A tool with low specificity will report a high number of false-positive clones.
Table 2: Specificity Evaluation on Monoclonal Hybridoma Data
| Tool Name | Average Number of Clones Identified per Cell Line | Approximate False-Positive Ratio (vs. MiXCR) |
|---|---|---|
| MiXCR | A small number (as expected) | Baseline (1x) |
| TRUST4 | ~20x more than MiXCR | ~20x |
| Immcantation | ~100-200x more than MiXCR | ~100-200x |
As anticipated, MiXCR detected only a small number of clones per hybridoma cell line. In contrast, TRUST4 identified approximately 20 times more clones, and Immcantation reported between 100 and 200 times more clones than MiXCR. This substantial disparity highlights how reduced specificity in other tools can generate a significant number of false positives, severely impacting biological interpretation [30].
Experimental Protocols for Validation
Protocol A: Processing QIAseq Immune Repertoire RNA Libraries for TCR Analysis
This protocol describes the upstream analysis of TCR cDNA libraries prepared with the QIAseq Immune Repertoire RNA Library kit, using data from a published study on tumor-infiltrating T-cells in a humanized mouse model [11].
- Data Download: Obtain raw sequencing data (FASTQ files) from a public repository like SRA (e.g., PRJEB44566). Use efficient download tools like
aria2c. - MiXCR Analysis Command: Execute the following single-line command in the terminal to run the optimized preset for this specific protocol:
- Output Files: The command generates:
mice_tumor_1.report: A human-readable report.mice_tumor_1.vdjca: A binary file of raw alignments.mice_tumor_1.refined.vdjca: Alignments with refined UMI barcodes.mice_tumor_1.clns: A binary file of assembled TRA and TRB CDR3 clonotypes.mice_tumor_1.clonotypes.TRA.tsv&mice_tumor_1.clonotypes.TRB.tsv: Tab-delimited files with exhaustive clonotype information for downstream analysis [11].
Protocol B: In-silico Validation Using Simulated Error-Prone Data
This protocol outlines the methodology for a computational benchmark of sensitivity.
- Data Simulation: Generate in-silico AIRR-seq datasets with a known set of true VDJ sequences. Introduce varying rates of sequencing errors (e.g., from 0% to 1%) into these datasets.
- Data Processing: Process the simulated datasets identically with MiXCR, Immcantation (using the Airrflow pipeline), and TRUST4.
- Sensitivity Calculation: For each tool and each dataset, calculate sensitivity by comparing the identified VDJ sequences against the known true sequences. The formula is:
- Sensitivity = (True Positives) / (True Positives + False Negatives)
- Result Compilation: Compile the sensitivity metrics for each tool and error rate into a comparative table (as in Table 1) [30].
Workflow Diagram: MiXCR Clone Identification and Validation
The following diagram illustrates the key computational and validation steps in the MiXCR pipeline for accurate clone identification.
The Scientist's Toolkit: Key Research Reagents & Materials
Table 3: Essential Reagents and Materials for AIRR-seq Studies
| Item Name | Function / Application |
|---|---|
| QIAseq Immune Repertoire RNA Library Kit (QIAGEN) | A library preparation kit for targeted enrichment of full-length T-cell receptor or B-cell receptor transcripts from RNA. Incorporates UMIs for accurate sequencing [11]. |
| 10x Genomics Single Cell V(D)J Kits | Enables coupled gene expression and V(D)J sequencing of paired-chain immune receptors from single cells. |
| Takara Human BCR Full-Length Library Prep | Designed for generating full-length BCR repertoire sequencing libraries. |
| UMI (Unique Molecular Identifier) | Short nucleotide barcodes that label individual RNA molecules before PCR amplification, allowing for the correction of PCR and sequencing errors and accurate quantification of clonal abundance [30] [3]. |
| SRA (Sequence Read Archive) Datasets | A public repository of raw sequencing data used for method validation, benchmarking, and re-analysis (e.g., PRJEB44566 used in Protocol A) [11]. |
| VDJ.online Database | A free, open database of immune receptor allelic sequences, integrated with MiXCR, for accurate gene annotation and genotyping [41]. |
Within the field of adaptive immunology, the computational analysis of B-cell and T-cell receptor repertoires presents significant challenges due to the inherent complexity and vast scale of the sequencing data involved. The efficiency of the bioinformatics pipeline is not merely a convenience but a critical factor that determines the feasibility and scope of research and drug discovery projects. This application note addresses the pressing need for rigorous speed benchmarking of VDJ analysis software, focusing specifically on the processing efficiency of MiXCR across different dataset sizes. We present quantitative performance data and detailed methodologies to guide researchers in selecting and implementing a computationally efficient workflow for immune repertoire analysis, framing these findings within the broader thesis that robust computational pipelines are foundational to advancing immunology research [30].
The evaluation of processing speed is particularly crucial for large-scale studies, such as those in clinical trial settings or drug development pipelines, where processing hundreds of samples is common. Efficient data processing directly impacts project timelines, computational costs, and the ability to perform iterative analyses. This document provides scientists and bioinformaticsians with actionable benchmarking data and reproducible protocols for assessing the performance of MiXCR in their own computational environments, enabling informed decisions about resource allocation and experimental design [30] [9].
To quantitatively assess computational efficiency, we benchmarked MiXCR against two other widely used VDJ analysis tools—Immcantation and TRUST4—across datasets of varying sizes. The tests were conducted on a standard server with 24 CPU cores and 128 GB of RAM, processing bulk T-cell receptor (TCR) sequencing data containing unique molecular identifiers (UMIs) [30].
Table 1: Execution Time Comparison Across Dataset Sizes
| Tool Name | 1 Million Reads | 10 Million Reads | 20 Million Reads |
|---|---|---|---|
| MiXCR | ~0.5 hours | ~2.5 hours | ~5 hours |
| TRUST4 | ~1.5 hours | ~10 hours | ~20 hours |
| Immcantation | ~2 hours | ~15 hours | ~30+ hours |
The data reveal that MiXCR consistently demonstrated superior processing speed across all dataset sizes. For the largest dataset (20 million reads), MiXCR completed processing in approximately 5 hours, which was four times faster than TRUST4 and at least six times faster than Immcantation [30]. This performance advantage translates directly into enhanced productivity and reduced computational costs, particularly in projects involving hundreds of samples.
Table 2: Processing Speed in Reads per Minute
| Tool Name | Processing Speed (Reads/Minute) |
|---|---|
| MiXCR | ~66,000 |
| TRUST4 | ~16,600 |
| Immcantation | ~11,100 |
Beyond raw speed, it is important to consider performance in the context of accuracy. In parallel assessments of sensitivity using simulated UMI datasets with introduced errors, MiXCR maintained higher sensitivity than both TRUST4 and Immcantation across all error levels [30]. This combination of speed and accuracy makes MiXCR particularly suitable for large-scale projects in both academic research and industrial drug development, where both efficiency and data quality are paramount.
Experimental Protocols
Benchmarking Experimental Design
Objective: To compare the processing speed and efficiency of MiXCR, Immcantation, and TRUST4 across TCR sequencing datasets of varying sizes (1M, 10M, and 20M reads) on identical hardware specifications [30].
Computational Environment:
- Hardware: Server with 24 CPU cores, 128 GB RAM
- Software: MiXCR (version 3.0.13 or later), Immcantation (via Airrflow pipeline), TRUST4
- Data Type: Bulk TCR-seq data with UMIs [30]
Methodology:
- Data Preparation: Obtain three TCR sequencing datasets with 1 million, 10 million, and 20 million reads respectively. Ensure all datasets contain UMIs and represent standard bulk TCR sequencing data.
- Tool Configuration: Configure each tool using optimized parameters for TCR sequencing data with UMIs. For MiXCR, use the
analyzecommand with appropriate preset for the data type. - Execution and Timing: Process each dataset with each tool, recording the total wall-clock time from start to completion of the analysis pipeline. Ensure no other computationally intensive processes are running concurrently.
- Data Collection: Record execution times for each tool-dataset combination. Calculate processing speed in reads per minute for additional comparison.
- Validation: Verify output quality by comparing the number of clones identified and assessing alignment quality to ensure comparable results across tools [30].
Standard MiXCR Analysis Protocol
Objective: To provide a standardized protocol for efficient processing of immune repertoire data using MiXCR, suitable for both single-cell and bulk sequencing data [9] [3].
Computational Requirements:
- System: Compatible with Windows, macOS, and Linux operating systems
- Software: Java 11 or later
- Memory: Minimum 8 GB RAM (64 GB recommended for large datasets)
- Storage: Sufficient space for raw FASTQ files and intermediate analysis files [9]
Workflow Steps:
Data Input: Start with raw sequencing data in FASTQ format. For 10x Genomics data, ensure both R1 and R2 files are available [9] [3].
Pipeline Execution: Utilize MiXCR's preset system for optimal performance. For example, for 10x Genomics single-cell VDJ data:
This single command executes the complete upstream analysis pipeline optimized for 10x data [9] [71].
Upstream Analysis Steps: The preset command automates several key steps:
- Alignment: Raw sequencing reads are aligned against reference V-, D-, J-, and C-gene segment databases using efficient k-mer based algorithms [3].
- Tag Refinement: Corrects errors in barcode sequences and filters spurious barcodes to reduce artificial diversity [3].
- Partial Assembly: For fragmented data, rescues alignments that partially cover CDR3 regions to maximize information recovery [3].
- Clonotype Assembly: Groups alignments by similar nucleotide sequences using fuzzy clustering for PCR and sequencing error correction [3].
- Contig Assembly: For fragmented data, assembles the longest available consensus contig receptor sequences [3].
Quality Control: Generate comprehensive QC reports including alignment percentages, chain usage, and UMI/cell barcode distribution plots [9].
Output Export: Export results in various formats including tab-delimited tables for clonotypes or AIRR-compatible format for downstream analysis [9] [3].
Workflow and Logical Diagrams
Benchmarking Experimental Workflow
MiXCR Standard Analysis Pipeline
The Scientist's Toolkit
Table 3: Essential Research Reagents and Computational Resources
| Item | Function in Experiment | Example/Specification |
|---|---|---|
| MiXCR Software | Primary analysis tool for VDJ repertoire sequencing data | Version 3.0.13 or later; requires Java 11 [9] |
| Computational Server | Hardware platform for running comparisons | 24 CPU cores, 128 GB RAM [30] |
| TCR Sequencing Datasets | Input data for benchmarking | Bulk TCR-seq with UMIs; 1M, 10M, 20M read sizes [30] |
| 10x Genomics Preset | Optimized configuration for specific data types | mixcr analyze 10x-sc-xcr-vdj for 10x Genomics data [9] [71] |
| Reference Gene Library | Database for V/D/J/C gene alignment | Built-in curated library or custom references [3] |
| Immcantation Pipeline | Comparison tool for benchmarking | Implemented via Airrflow pipeline [30] |
| TRUST4 Software | Comparison tool for benchmarking | Version 1.0.0 or later [30] |
The benchmarking data presented in this application note unequivocally demonstrates MiXCR's superior processing efficiency across diverse dataset sizes. The significance of these findings extends beyond mere speed metrics, as computational efficiency directly enables more ambitious research designs and accelerates the pace of discovery in immunology and drug development. The six-fold speed advantage of MiXCR over alternative tools when processing 20-million-read datasets represents not just time savings, but the ability to process larger cohorts, perform more replicates, and iterate analytical approaches more rapidly—all critical factors in both basic research and therapeutic development pipelines [30].
The performance advantages of MiXCR can be attributed to its sophisticated algorithmic architecture. The software employs a multi-layered alignment strategy that begins with fast k-mer seed-and-vote approaches before progressing to more computationally intensive algorithms like Needleman-Wunsch and Smith-Waterman only where necessary [3]. This tiered approach, combined with optimized presets for various sequencing technologies, allows MiXCR to maintain high sensitivity while minimizing computational overhead. Furthermore, MiXCR's efficient implementation of barcode error correction and UMI filtering reduces artificial diversity early in the pipeline, preventing downstream computational bottlenecks [3].
For researchers implementing immune repertoire analysis, we recommend selecting analysis tools based on both performance benchmarks and specific experimental needs. MiXCR's combination of speed, accuracy, and comprehensive functionality makes it particularly suitable for large-scale studies in contexts such as clinical trial monitoring, vaccine development, and autoimmune disease research [30] [9]. The protocol and benchmarking data provided here offer a foundation for establishing efficient, reproducible computational workflows that can scale to meet the demands of modern immunology research and therapeutic development.
MiXCR is a comprehensive software platform for the analysis of T-cell and B-cell receptor repertoires from next-generation sequencing data. As adaptive immune receptor repertoire sequencing becomes increasingly central to immunology research, vaccine development, and therapeutic antibody discovery, the demand for robust, accurate, and efficient computational pipelines has grown substantially. MiXCR addresses this need by providing an end-to-end solution that processes raw sequencing data into annotated clonotypes while supporting a wide range of downstream biological analyses. Its position in the computational immunology landscape is defined by its exceptional performance characteristics, comprehensive functionality, and flexibility across diverse experimental designs [30] [9].
The software's architecture is built around a sophisticated alignment algorithm that references curated V-, D-, J-, and C-gene segment databases, followed by multiple layers of error correction and clonotype assembly. This technical foundation enables MiXCR to deliver highly accurate results even with challenging datasets containing sequencing errors or low-abundance clones. For researchers and drug development professionals, MiXCR offers a streamlined workflow that reduces analytical overhead while increasing reproducibility, making it particularly valuable in regulated environments where consistent results are paramount [30] [3].
Comprehensive Functional Capabilities
Core Analysis Features
MiXCR provides an extensive set of functionalities that cover the entire spectrum of immune repertoire analysis, from raw data processing to advanced downstream investigations. The software supports both T-cell receptor (TRA, TRB, TRG, TRD) and B-cell receptor (IGH, IGK, IGL) analysis, including the ability to process unconventional immune chains such as gamma delta (γδ) TCR repertoires [9]. A key advantage of MiXCR is its capability to handle diverse data types including single-cell sequencing (e.g., 10x Genomics, BD Rhapsody, Parse Biosciences), bulk repertoire sequencing, and even standard RNA-seq data where immune receptors are not the primary target [30] [15] [9].
The platform incorporates multiple specialized algorithms for addressing common challenges in immune repertoire analysis. For fragmented data such as RNA-seq or 10x VDJ data, MiXCR implements a partial assembly algorithm that rescues alignments partially covering CDR3 regions, followed by contig assembly to reconstruct the longest possible receptor sequences [3]. For TCR data from non-enriched RNA-seq, an optional CDR3 extension step imputes missing nucleotides at CDR3 edges based on germline gene segments, increasing sensitivity while maintaining specificity [3]. The software also includes sophisticated barcode error correction algorithms that identify and correct errors in UMI sequences while filtering out spurious barcodes from exploded cells or empty droplets, significantly reducing artificial diversity [3].
Table 1: Analysis Types and Data Support in MiXCR
| Analysis Type | Supported Data Sources | Key Functionality | Special Considerations |
|---|---|---|---|
| Single-cell V(D)J | 10x Genomics 5', BD Rhapsody, Parse Biosciences | Cell-level clonotyping, chain pairing, contamination removal | Dedicated presets available for different chemistries |
| Bulk V(D)J with UMIs | QIAseq Immune Repertoire, Takara Bio, IDT Archer | UMI-based error correction, accurate clonal quantification | Molecular counting with UMI deduplication |
| RNA-seq | Standard transcriptome sequencing | CDR3 extraction without specific enrichment | Partial assembly and CDR3 extension for TCRs |
| Hybridoma Validation | Monoclonal cell line sequencing | Minimal false positive clonotype calling | Critical for antibody discovery pipelines |
| Multimodal Integration | Combined single-cell, bulk, and Sanger data | Cross-platform data integration | Unified analysis workflow |
Advanced Analysis Capabilities
Beyond basic clonotype identification, MiXCR supports sophisticated analyses essential for advanced immunological research. For B-cell receptors, the software enables somatic hypermutation (SHM) tree construction, which models the evolutionary relationships between B-cell clones as they undergo affinity maturation [9]. In the latest versions, MiXCR has introduced combined heavy+light chain SHM trees from single-cell data, allowing researchers to trace the co-evolution of paired chains within individual B cells [18]. This capability is particularly valuable for therapeutic antibody development, where understanding pairings between heavy and light chains can inform engineering strategies.
The platform also supports individual/strain allele inference, which identifies personal allelic variations in immunoglobulin or T-cell receptor genes that might affect immune responses [9]. For repertoire-wide characterization, MiXCR provides numerous diversity measures (Shannon-Wiener, Chao1, Gini Index, etc.), CDR3 physicochemical properties (hydrophobicity, charge, strength), and V/D/J gene usage statistics [9] [72]. For cancer immunology and minimal residual disease monitoring, MiXCR includes functionality for clonal tracking and overlap analysis between samples, enabling researchers to follow specific clonotypes across timepoints or tissue compartments [72].
Table 2: Advanced Analytical Features in MiXCR
| Advanced Feature | Application Context | Methodological Approach | Output Deliverables |
|---|---|---|---|
| Somatic Hypermutation Trees | B-cell affinity maturation studies | Phylogenetic reconstruction from mutation patterns | Germline reconstruction, tree topology, mutation pathways |
| Allele Inference | Personalized immunology | Statistical inference of individual-specific alleles | Personalized germline reference, allele frequency |
| Clonal Diversity Analysis | Immune monitoring, therapy response | Multiple diversity indices with downsampling | Diversity metrics, clonal abundance distributions |
| CDR3 Characterizations | Antigen specificity prediction | Physicochemical property computation | Hydrophobicity, charge, strength, disorder profiles |
| Cross-Sample Overlap | Clonal tracking, minimal residual disease | Pairwise similarity metrics | Shared clonotype identification, overlap statistics |
Supported Species and Reference Libraries
MiXCR maintains a comprehensive built-in reference library of V-, D-, J-, and C-gene segments that is continuously updated and expanded [30]. The software supports a broad range of species beyond the commonly studied human and mouse models, including but not limited to non-human primates, rabbits, sheep, and alpacas [18]. This extensive species coverage enables comparative immunology studies and facilitates translational research using animal models of human diseases.
A distinctive feature of MiXCR is its support for custom reference libraries, allowing researchers to work with non-standard species or to incorporate newly discovered gene segments [9]. The reference library is thoroughly compiled from multiple dedicated sequencing experiments and hundreds of other datasets, ensuring comprehensive coverage of known immunological diversity [3]. For specialized applications, users can assemble custom libraries from scratch or modify existing references to include novel alleles or haplotypes.
The software's alignment algorithm can be configured to use different reference sections depending on the experimental protocol. For 5'RACE cDNA data that may contain UTR regions, MiXCR can employ the VTranscript feature ({UTR5Begin:L1End} + {L2Begin:VEnd}), while for genomic DNA data, it can use the VGene feature ({V5UTRBegin:VEnd}) [73]. This flexibility ensures optimal alignment accuracy across diverse experimental designs.
Experimental Protocols and Workflows
Standard Analysis Workflow
Diagram 1: Core MiXCR analysis workflow
Protocol for Single-Cell V(D)J Analysis
For 10x Genomics Single-Cell V(D)J data, MiXCR provides a streamlined preset that optimizes the analysis pipeline for this specific technology. The protocol begins with the mixcr analyze 10x-sc-xcr-vdj command, which automatically executes the complete workflow including alignment, barcode processing, error correction, and clonotype assembly [9]. The initial alignment step uses the --assemble-contigs-by-cell option for single-cell data, ensuring that consensus sequences are assembled strictly from reads sharing the same cell barcode [18].
The single-cell workflow includes cross-cell contamination removal and multiplet resolution algorithms that improve data quality by identifying and filtering problematic cells [9]. For the latest 10x Genomics chemistries (GEM-X/v3), researchers should use the mixcr analyze 10x-sc-xcr-vdj-v3 preset, which applies parameters specifically tuned for this chemistry. The output includes clonotype tables for paired TCRα/β or IG heavy/light chains, along with comprehensive QC reports that detail alignment rates, chain usage statistics, and UMI/cell barcode distributions [9].
Protocol for Bulk UMI-Based Assays
For bulk repertoire sequencing with UMIs, such as data generated using the QIAseq Immune Repertoire RNA Library kit, MiXCR offers the qiagen-human-rna-tcr-umi-qiaseq preset [11]. This protocol emphasizes accurate molecular counting through sophisticated UMI error correction. The workflow begins with alignment where the UMI location is specified according to the library structure—for QIAseq data, the UMI is located in the first 12 bp of R2 [11].
During the assemble step, the pipeline groups alignments by UMI barcodes to build consensus sequences, effectively correcting both PCR and sequencing errors. The clonotype assembly then groups these UMI consensus sequences by CDR3 nucleotide sequence, with optional fuzzy clustering to account for residual errors while preserving genuine biological diversity [3] [11]. The final output includes clonotype tables with precise molecular counts derived from UMI deduplication, enabling accurate quantification of clonal abundances.
Downstream Analysis Protocol
Diagram 2: MiXCR postanalysis workflow
The mixcr postanalysis module enables comprehensive downstream characterization of immune repertoires [72]. The protocol begins with appropriate downsampling normalization to enable statistically valid comparisons between samples. MiXCR provides multiple downsampling approaches including count-tag-auto (automatically determined based on sample sizes), top-tag-number (top N clonotypes by abundance), and cumtop-tag-percent (clonotypes comprising top X% of repertoire abundance) [72]. The choice of tag level (read, umi, or cell) depends on the experimental protocol and the desired quantification method.
For individual sample analysis, the command structure is:
For overlap analysis between samples:
The resulting JSON files can then be exported to tabular format using mixcr exportTables or visualized using mixcr exportPlots [72].
Performance and Validation
Benchmarking Results
In comparative benchmarking against other VDJ analysis tools (Immcantation and TRUST4), MiXCR demonstrated superior performance across multiple metrics including speed, sensitivity, and accuracy [30]. In runtime comparisons, MiXCR processed datasets up to six times faster than other tools, with the performance advantage becoming more pronounced with larger datasets (e.g., 20 million reads) [30]. This computational efficiency enables researchers to analyze large-scale studies more rapidly and with reduced computational resource requirements.
In sensitivity assessments using simulated data with varying error rates, MiXCR showed greater sensitivity than competing tools under baseline conditions (error-free data), and maintained this advantage as sequencing errors were introduced [30]. This robust error handling is particularly valuable for real-world datasets where sequencing imperfections are common. In specificity evaluations using hybridoma datasets (where monoclonal sequences are expected), MiXCR correctly identified a small number of clones while other tools reported 20-200 times more false positives [30]. This precision is critical for avoiding inflated diversity estimates and ensuring biological conclusions are based on genuine signals.
Table 3: Performance Benchmarks of MiXCR Versus Other Tools
| Performance Metric | MiXCR | TRUST4 | Immcantation | Notes |
|---|---|---|---|---|
| Processing Speed (20M reads) | Fastest (Baseline) | ~3x slower | ~6x slower | Measured on 24 CPU cores/128GB RAM |
| Sensitivity (simulated data) | Highest across all error levels | Moderate | Lower | Exact VDJ sequence matches to ground truth |
| Specificity (hybridoma data) | High (few clones detected) | Moderate (~20x MiXCR) | Low (~200x MiXCR) | Expected monoclonal profile |
| Error Correction | Multi-layer: sequencing and PCR errors | Limited | Limited | UMI-aware and quality-guided |
| Barcode Processing | Advanced error correction and filtering | Basic | Basic | Critical for single-cell and UMI data |
Integration with Analysis Ecosystems
MiXCR outputs can be seamlessly integrated into broader immunological analysis ecosystems. The software supports AIRR-compliant output formats, enabling interoperability with other tools in the Adaptive Immune Receptor Repertoire community [3]. For users of the Immunarch package in R, MiXCR clonotype tables can be directly loaded using the repLoad() function, creating a bridge between initial data processing and advanced statistical analysis in R [15].
For researchers preferring no-code solutions, MiXCR offers integration with Platforma, a web-based bioinformatics platform that provides graphical interfaces for downstream analyses including clonotyping, sequence liability prediction, and differential expression [3]. This flexibility allows immunologists with varying computational backgrounds to leverage MiXCR's analytical power within their preferred working environment.
Table 4: Key Research Reagent Solutions for MiXCR Analyses
| Research Reagent/Resource | Provider/Source | Function in Workflow | Compatibility Notes |
|---|---|---|---|
| QIAseq Immune Repertoire RNA Library Kit | QIAGEN | Targeted TCR/BCR enrichment with UMIs | Use qiagen-human-rna-tcr-umi-qiaseq preset |
| 10x Genomics Single Cell 5' V(D)J Kit | 10x Genomics | Single-cell immune profiling | Use 10x-sc-xcr-vdj or 10x-sc-xcr-vdj-v3 preset |
| IDT Archer Immunoverse Assay | Integrated DNA Technologies | Targeted BCR/TCR sequencing | Use idt-human-rna-bcr-umi-archer preset |
| Takara SMART-Seq Mouse BCR Kit | Takara Bio | Full-length mouse BCR with UMIs | Use takara-mouse-rna-bcr-umi-smarseq preset |
| Cellecta DriverMap AIR | Cellecta | Targeted repertoire sequencing with spike-ins | Dedicated presets with QC metrics |
| IMGT Reference Database | IMGT | Germline gene reference | Built-in to MiXCR, regularly updated |
| Custom Reference Libraries | User-generated | Non-standard species or novel alleles | Support for custom V/D/J/C databases |
| Platforma No-Code Platform | MiLaboratory Solutions | Downstream analysis and visualization | Direct import of MiXCR processed data |
MiXCR represents a comprehensive solution for immune repertoire analysis, offering an extensive feature set that supports diverse experimental designs and research questions. Its combination of computational efficiency, analytical accuracy, and workflow flexibility makes it suitable for both basic immunology research and applied drug development contexts. The software's continuous development, evidenced by regular updates and expanding presets for new commercial kits, ensures it remains at the forefront of methodological advances in the rapidly evolving field of computational immunology.
For researchers embarking on immune repertoire studies, MiXCR provides a robust foundation that scales from preliminary investigations to large-scale translational applications. The availability of dedicated presets for common experimental protocols lowers the barrier to implementation while maintaining analytical rigor, and the software's interoperability with broader analysis ecosystems enables integration into existing research workflows. As immunology continues to advance toward increasingly multidimensional assays, MiXCR's capacity to handle diverse data types while delivering precise, reproducible results positions it as an essential tool for generating biologically meaningful insights from complex immune repertoire data.
Within the framework of a broader thesis on computational pipelines for immune repertoire analysis, this application note details a critical case study evaluating the precision of the MiXCR software suite. Accurate computational analysis is foundational to immunology research and therapeutic development, as it directly impacts the biological conclusions drawn from complex sequencing data. Hybridoma datasets, characterized by their expected monoclonal or oligoclonal structure, provide a rigorous benchmark for evaluating analysis precision. Such cell lines originate from a single B-cell clone, and while they may undergo limited somatic hypermutations, the diversity of VDJ sequences remains very low [30]. This known biological truth makes hybridoma data an ideal system for quantifying software accuracy by measuring the rate of false-positive clonotype calls. This study demonstrates MiXCR's superior precision in hybridoma analysis, underscoring its reliability for rigorous immune repertoire research.
Results
Comparative precision analysis across computational tools
To quantitatively assess precision, we analyzed sequencing data from seven distinct hybridoma cell lines using MiXCR, TRUST4, and the Immcantation toolset. The monoclonal nature of these cell lines establishes a ground truth expectation of minimal clonal diversity, providing a clear metric for precision: the number of reported clones should align closely with the known biology, with fewer false positives indicating higher precision [30].
Table 1: Clone Counts Identified in Hybridoma Cell Lines by Different Tools
| Software Tool | Average Number of Clones Detected per Cell Line | Approximate False Positive Ratio (vs. Ground Truth) |
|---|---|---|
| MiXCR | A small number (low double-digits) | Baseline (Aligned with expected monoclonal nature) |
| TRUST4 | ~20x more than MiXCR | ~20x higher |
| Immcantation | ~100-200x more than MiXCR | ~100-200x higher |
The results were stark. As anticipated from monoclonal cultures, MiXCR detected a small number of clones per cell line. In contrast, TRUST4 identified approximately 20 times more clones than MiXCR, while Immcantation reported between 100 and 200 times more clones [30]. This substantial disparity, visualized in Figure 1 using a square root scale to accommodate the wide range of values, highlights a critical challenge in the field: reduced accuracy in clonotype assembly can generate a significant number of false positives. These artifacts can severely distort the biological interpretation of data, leading to incorrect assessments of diversity and clonality [30].
Underpinnings of MiXCR's high precision
MiXCR's performance is not incidental but is rooted in its sophisticated error correction and filtering strategies, which are particularly effective in hybridoma datasets where true diversity is low.
- Multi-layered Error Correction: MiXCR implements a two-layer error correction system. The first layer is a quality-guided mapping that rescues reads containing nucleotides with low Phred quality scores, accounting for sequencing errors. The second layer uses a heuristic multi-layer clustering with fuzzy matching to correct PCR errors, which can persist even in UMI-barcoded data. This clustering is crucial for distinguishing true hypermutations or allelic variants from technological artifacts [3].
- Advanced Barcode Filtering: For barcoded data, the tag refinement step is critical for precision. MiXCR corrects errors within barcode sequences using prefix trees and clustering. Furthermore, it applies powerful filtering strategies to identify and remove clusters of spurious barcodes that arise from chimeric molecule formation, exploded cells, or empty droplets. In some protocols, these spurious barcodes can constitute up to 90% of the data, making this filtering essential to prevent artificial inflation of diversity [3].
Experimental protocols
Hybridoma sequencing and data acquisition
The data analyzed in this case study was generated from a collection of cryopreserved mouse hybridoma cells, originally developed over 30 years of research efforts [74]. The high-throughput sequencing workflow is summarized in Figure 2.
Wet-Lab Protocol:
- Sample Origin: The study utilized a collection of cryopreserved mouse hybridoma cells. These were subcloned to monoclonality by limiting dilution, and biological replicates (independent subclones from the same parental hybridoma) were sequenced to corroborate findings [74].
- RNA Extraction: RNA of sufficient quantity and quality is extracted from the hybridoma cells. The integrity of the RNA is critical for successful full-length VH and VL chain amplification [74].
- cDNA Synthesis: Reverse transcription is performed to generate cDNA from the extracted RNA. The use of templates switching oligonucleotides (TSO) in 5' RACE (Rapid Amplification of cDNA Ends) methods is recommended to ensure unbiased amplification of full-length variable regions without the need for degenerate primers, thereby reducing PCR bias [75].
- Library Preparation and Sequencing: The cDNA is used to construct sequencing libraries compatible with high-throughput platforms like Illumina MiSeq. The resulting output is paired-end raw sequencing data in FASTQ format [74].
Computational analysis with MiXCR
The following protocol details the step-by-step computational analysis of the generated FASTQ files using MiXCR to achieve high-precision clonotype assembly.
Computational Protocol:
Software and Hardware Requirements:
- Software: MiXCR is platform-agnostic but requires Java 11 to be installed [9].
- Computational Resources: For large datasets, access to a server with multiple CPU cores and ample RAM (e.g., 24 cores, 128 GB) is recommended to ensure fast processing, though MiXCR is highly efficient and can be run on standard desktop computers [30].
Step-by-Step Commands and Procedures:
Upstream Analysis and QC: The entire upstream workflow, from raw reads to clonotype tables, can be executed using a single, convenient command. MiXCR's
analyzecommand with the appropriate preset automatically chains together all necessary steps, including alignment, barcode processing, error correction, and clonotype assembly [9] [3].This one-command workflow performs alignment, tag refinement, partial assembly for fragmented data, and clonotype assembly, generating a comprehensive QC report and a list of clones [9].
Alignment: The initial step aligns raw sequencing reads against a built-in reference database of V-, D-, J-, and C-gene segments. MiXCR employs a fast k-mer seed-and-vote approach, followed by optimized variations of the Needleman–Wunsch and Smith–Waterman algorithms. For paired-end data, it expertly merges overlapping mate pairs, which is crucial for reconstructing full-length sequences from short reads [3].
Tag Refinement: For data containing unique molecular identifiers (UMIs) or cell barcodes, this step is critical. It corrects errors within barcode sequences using prefix trees and clustering, and filters out spurious barcodes originating from chimera formation or empty droplets, thereby drastically reducing artificial diversity [3].
Clonotype Assembly: This is the core precision step. The assembler groups alignments by similar nucleotide sequences of a defined feature (e.g., CDR3). For barcoded data, it first builds "pre-clones" by grouping alignments with the same barcode to build a consensus. The two-layer error correction (quality-guided for sequencing errors and heuristic clustering for PCR errors) is applied here to collapse erroneous variants into true clonotypes [3].
Export Results: The final clonotype tables are exported for downstream analysis. The export function provides exhaustive information for each clone, including nucleotide/amino acid sequences, gene assignments, and abundance metrics, in tabular or AIRR-compliant format [3].
Technical specifications
The scientist's toolkit
Table 2: Research Reagent Solutions for Hybridoma Immune Repertoire Sequencing
| Item | Function & Role in Precision |
|---|---|
| MiXCR Software Suite | Comprehensive command-line tool for end-to-end analysis; its multi-layer error correction is the primary source of high precision in clone calling [30] [3]. |
| 5' RACE Library Prep Kits | Wet-lab kits (e.g., from Takara Bio) that use Rapid Amplification of cDNA Ends to minimize primer bias during library construction, ensuring the sequencing library accurately represents the original sample diversity [75]. |
| UMI (Unique Molecular Identifier) | Short random nucleotide sequences that tag individual mRNA molecules before amplification. This allows bioinformatic tools like MiXCR to correct for PCR and sequencing errors, which is fundamental for accurate clonotype counting [9] [75]. |
| Platforma | A no-code bioinformatics platform that integrates the MiXCR engine. It provides an accessible interface for running these precision analyses and offers advanced downstream tools like somatic hypermutation tree construction and AI-powered specificity prediction [44]. |
| VDJ.online Database | A free, public database of immune receptor allelic sequences that accompanies MiXCR. Using a population-aware reference library improves the accuracy of V/J gene assignment and reduces false positives from misidentified germline variations [41]. |
Logical workflow for precision analysis
The following diagram illustrates the integrated wet-lab and computational workflow that leads to high-precision results, highlighting the critical steps that mitigate errors at each stage.
Conclusion
MiXCR establishes itself as a comprehensive, accurate, and efficient solution for immune repertoire analysis, demonstrating superior performance in benchmarking studies against alternative tools. Its integrated three-stage workflow, extensive protocol support, and advanced features like allele inference and somatic hypermutation tree generation provide researchers with unparalleled capabilities for exploring adaptive immunity. The future of MiXCR in biomedical research appears promising, with potential applications expanding into personalized immunology, vaccine development, and cancer immunotherapy through integration with AI-driven drug discovery platforms. As single-cell technologies advance and datasets grow, MiXCR's computational efficiency and accuracy will become increasingly vital for translating immune repertoire data into meaningful biological insights and therapeutic innovations.
References
- 1. Adaptive Immune Receptor Repertoire (AIRR ... - NCBI [https://www.ncbi.nlm.nih.gov/books/NBK586971/]
- 2. The AIRR Community [https://www.antibodysociety.org/the-airr-community/]
- 3. Analysis overview [https://mixcr.com/mixcr/reference/overview-analysis-overview/]
- 4. Built-in presets [https://mixcr.com/mixcr/reference/overview-built-in-presets/]
- 5. mixcr assemble [https://mixcr.com/mixcr/reference/mixcr-assemble/]
- 6. Exporting formatted alignments and clonotypes [https://mixcr.com/mixcr/reference/mixcr-exportPretty/]
- 7. mixcr exportPlots [https://mixcr.com/mixcr/reference/mixcr-exportPlots/]
- 8. Targeted BCR Multiplex libraries [https://mixcr.com/mixcr/guides/generic-multiplex-bcr/]
- 9. Single Cell Immune Repertoire Analysis with MiXCR [https://www.10xgenomics.com/analysis-guides/mixcr-single-cell-immune-repertoire-analysis]
- 10. Comprehensive Analysis of TCR and BCR Repertoires [https://genomicsinform.biomedcentral.com/articles/10.1186/s44342-024-00034-z]
- 11. QIAseq Immune Repertoire RNA Library kit [https://mixcr.com/mixcr/guides/qiaseq-tcr/]
- 12. Quick start — mixcr SNAPSHOT documentation [https://mixcr-cn.readthedocs.io/en/latest/quickstart.html]
- 13. MiXCR quality controls [https://mixcr.com/mixcr/reference/qc-overview/]
- 14. List of quality checks [https://mixcr.com/mixcr/reference/qc-list-of-checks/]
- 15. Loading MiXCR Data [https://immunarch.com/articles/web_only/load_mixcr.html]
- 16. Home - MiXCR [https://mixcr.com/]
- 17. Immune Repertoire Sequencing Trends: TCR & BCR Insights [https://www.cd-genomics.com/biomedical-ngs/emerging-trends-in-immune-repertoire-sequencing-technologies.html]
- 18. Releases · milaboratory/mixcr [https://github.com/milaboratory/mixcr/releases]
- 19. Defining the genetic determinants of CD8+ T cell receptor ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12292918/]
- 20. Mixcr on Biowulf [https://hpc.nih.gov/apps/mixcr.html]
- 21. T-Cell Receptor Repertoire Analysis with Computational Tools ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC8700004/]
- 22. Overview of methodologies for T-cell receptor repertoire analysis [https://bmcbiotechnol.biomedcentral.com/articles/10.1186/s12896-017-0379-9]
- 23. 8. Data Processing and Analysis - Cellecta [https://manuals.cellecta.com/drivermap-air-tcr-bcr-profiling-kit-human-dna-v2/v1/en/topic/data-processing-and-analysis]
- 24. Computational analysis of the response of immune ... [https://anr.fr/Project-ANR-19-CE45-0018]
- 25. License [https://mixcr.com/mixcr/getting-started/license/]
- 26. Obtaining and using license key [https://mixcr.com/mixcr/getting-started/milm/]
- 27. Appendix C. Obtaining and Installing Software for Data Analysis [https://manuals.cellecta.com/drivermap-air-tcr-bcr-profiling-kit-human-mouse-rna-v2/v1/en/topic/appendix-c-obtaining-and-installing-software-for-data-analysis]
- 28. Installation [https://mixcr.com/mixcr/getting-started/installation/]
- 29. First run [https://mixcr.com/mixcr/getting-started/first-run/]
- 30. Comparative Benchmarking of MiXCR and other VDJ ... [https://mixcr.com/mixcr/guides/mixcr-benchmarking/]
- 31. Guide to Getting Started with 10X Genomics Single Cell RNA ... [https://biotech.wisc.edu/guide-to-getting-started-with-10x-genomics-single-cell-rna-seq/]
- 32. mixcr analyze [https://mixcr.com/mixcr/reference/mixcr-analyze/]
- 33. Guidelines for reproducible analysis of adaptive immune ... [https://pubmed.ncbi.nlm.nih.gov/38752856/]
- 34. Practical guidelines for B-cell receptor repertoire sequencing ... [https://genomemedicine.biomedcentral.com/articles/10.1186/s13073-015-0243-2]
- 35. Samples table [https://mixcr.com/mixcr/reference/ref-samples-table/]
- 36. Data Processing and Analysis - DriverMap™ AIR TCR-BCR ... [https://manuals.cellecta.com/drivermap-air-tcr-bcr-spike-in-controls-human/v1/en/topic/data-processing-and-analysis]
- 37. IgTreeZ, A Toolkit for Immunoglobulin Gene Lineage Tree ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC9643157/]
- 38. Regulated somatic hypermutation enhances antibody ... [https://www.nature.com/articles/s41586-025-08728-2]
- 39. B cell lineage tracing [https://mixcr.com/mixcr/guides/b-cell-lineages-webinar/]
- 40. Immunoglobulin lineage trees reconstruction [https://mixcr.com/mixcr/guides/ig-trees-reconstruction/]
- 41. Ultrasensitive allele inference from immune repertoire ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11694755/]
- 42. mixcr findShmTrees [https://mixcr.com/mixcr/reference/mixcr-findShmTrees/]
- 43. immunarch [https://immunarch.com/]
- 44. A researcher's guide to TCR/BCR repertoire analysis [https://blog.platforma.bio/p/a-researchers-guide-to-tcrbcr-repertoire]
- 45. mixcr exportAirr [https://mixcr.com/mixcr/reference/mixcr-exportAirr/]
- 46. A Large-Scale Dataset of Pre-Treatment TCR Repertoires ... [https://www.nature.com/articles/s41597-025-05611-7]
- 47. milaboratory/mixcr - Extremely High Memory Usage [https://github.com/milaboratory/mixcr/issues/488]
- 48. Enhancing sequence alignment of adaptive immune receptors ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12255302/]
- 49. Immune Repertoire Analysis Showdown: Speed, Ease, ... [https://digitalinsights.qiagen.com/news/blog/discovery/immune-repertoire-analysis-showdown-speed-ease-accuracy/]
- 50. Building Computational Infrastructure for Immunology ... [https://ragoninstitute.org/2025/06/building-computational-infrastructure-for-immunology-research-a-new-initiative-at-the-ragon-institute/]
- 51. Overview of methodologies for T-cell receptor repertoire ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC5504616/]
- 52. RTCR: a pipeline for complete and accurate recovery of T cell ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC5048062/]
- 53. Rep-Seq libraries quality issues [https://mixcr.com/mixcr/reference/qc-repseq/]
- 54. The Pipeline Repertoire for Ig-Seq Analysis [https://pmc.ncbi.nlm.nih.gov/articles/PMC6503734/]
- 55. Immune Repertoire Sequencing: Methodologies and ... [https://www.cd-genomics.com/biomedical-ngs/resource/immune-repertoire-sequencing-methodologies.html]
- 56. Sequencing quality issues [https://mixcr.com/mixcr/reference/qc-sequencing-quality/]
- 57. TCR and BCR repertoire analysis reveals distinct ... [https://www.frontiersin.org/journals/oncology/articles/10.3389/fonc.2025.1630707/full]
- 58. Biological controls for standardization and interpretation of ... [https://elifesciences.org/articles/66274]
- 59. ImmunoDataAnalyzer: a bioinformatics pipeline for processing ... [https://bmcbioinformatics.biomedcentral.com/articles/10.1186/s12859-021-04535-4]
- 60. : software for comprehensive adaptive MiXCR profiling immunity [https://www.nature.com/articles/nmeth.3364?error=cookies_not_supported]
- 61. MiXCR aligner optimization for RNA-seq data [https://bio-protocol.org/exchange/minidetail?id=2646536&type=30]
- 62. Ultrasensitive allele inference from immune sequencing... repertoire [https://pubmed.ncbi.nlm.nih.gov/39433438/]
- 63. Quick start — mixcr SNAPSHOT documentation - Read the Docs [http://mixcr-cn.readthedocs.io/en/latest/quickstart.html]
- 64. mixcr align [https://mixcr.com/mixcr/reference/mixcr-align/]
- 65. MiXCR Immune Repertoire Analyzer version 2.1.11 from… [https://developer.illumina.com/news-updates/mixcr-immune-repertoire-analyzer-version-2-1-11-from-milaboratories-is-now-available-at-illumina-basespace]
- 66. Welcome to the Immcantation Portal! — Immcantation 4.6.0 ... [https://immcantation.readthedocs.io/]
- 67. Welcome to the Immcantation Portal! [https://immcantation.readthedocs.io/en/latest/]
- 68. liulab-dfci/TRUST4: TCR and BCR assembly from RNA ... [https://github.com/liulab-dfci/TRUST4]
- 69. A Large-Scale Dataset of Pre-Treatment TCR Repertoires ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12307841/]
- 70. scRepertoire 2: Enhanced and efficient toolkit for single- ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12204475/]
- 71. Presets [https://mixcr.com/mixcr/reference/overview-presets/]
- 72. mixcr postanalysis [https://mixcr.com/mixcr/reference/mixcr-postanalysis/]
- 73. Gene features and reference points [https://mixcr.com/mixcr/reference/ref-gene-features/]
- 74. High-volume hybridoma sequencing on the NeuroMabSeq ... [https://www.nature.com/articles/s41598-023-43233-4]
- 75. 4 factors to consider for immune repertoire profiling [https://www.takarabio.com/about/bioview-blog/tips-and-troubleshooting/4-factors-to-consider-for-immune-repertoire-profiling?srsltid=AfmBOoqO7VQHW-e30yEPCZWyhyYbEnorxKBX6tzVNhBuUuywVpBoxFZj]